Redux Essentials, Часть 8: Продвинутые паттерны RTK Query
Эта страница переведена PageTurner AI (бета). Не одобрена официально проектом. Нашли ошибку? Сообщить о проблеме →
- Как использовать теги с идентификаторами для управления инвалидацией кэша и повторными запросами
- Как работать с кэшем RTK Query вне React
- Техники обработки данных ответов
- Реализация оптимистичных обновлений и потоковых обновлений
- Завершение Части 7 для понимания настройки и базового использования RTK Query
Введение
В Части 7: Основы RTK Query мы рассмотрели настройку и использование RTK Query API для работы с получением данных и кэшированием в приложении. Мы добавили "API слой" в Redux хранилище, определили "query" эндпоинты для получения данных постов и "mutation" эндпоинт для добавления новых постов.
В этом разделе мы продолжим миграцию примера приложения на использование RTK Query для других типов данных и рассмотрим продвинутые возможности для упрощения кодовой базы и улучшения пользовательского опыта.
Некоторые изменения в этом разделе не являются строго обязательными — они включены для демонстрации возможностей RTK Query и показывают, что вы можете делать, чтобы вы понимали, как использовать эти функции при необходимости.
Редактирование постов
Мы уже добавили mutation эндпоинт для сохранения новых постов на сервер и использовали его в <AddPostForm>. Далее нам нужно обновить <EditPostForm> для редактирования существующих постов.
Обновление формы редактирования поста
Как и при добавлении постов, первый шаг — определить новый mutation эндпоинт в API слое. Он будет похож на эндпоинт добавления поста, но должен включать ID поста в URL и использовать HTTP PATCH запрос, указывающий на частичное обновление полей.
export const apiSlice = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
tagTypes: ['Post'],
endpoints: builder => ({
getPosts: builder.query<Post[], void>({
query: () => '/posts',
providesTags: ['Post']
}),
getPost: builder.query<Post, string>({
query: postId => `/posts/${postId}`
}),
addNewPost: builder.mutation<Post, NewPost>({
query: initialPost => ({
url: '/posts',
method: 'POST',
body: initialPost
}),
invalidatesTags: ['Post']
}),
editPost: builder.mutation<Post, PostUpdate>({
query: post => ({
url: `posts/${post.id}`,
method: 'PATCH',
body: post
})
})
})
})
export const {
useGetPostsQuery,
useGetPostQuery,
useAddNewPostMutation,
useEditPostMutation
} = apiSlice
После добавления мы можем обновить <EditPostForm>. Компонент должен прочитать оригинальный Post из хранилища, использовать его для инициализации состояния компонента для редактирования полей, а затем отправить обновленные изменения на сервер. Сейчас мы читаем Post через selectPostById и вручную диспатчим postUpdated thunk для запроса.
Мы можем использовать тот же хук useGetPostQuery, что и в <SinglePostPage>, для чтения записи Post из кэша в хранилище, а новый хук useEditPostMutation — для сохранения изменений. При желании можно добавить индикатор загрузки и заблокировать поля формы во время обновления.
import React from 'react'
import { useNavigate, useParams } from 'react-router-dom'
import { Spinner } from '@/components/Spinner'
import { useGetPostQuery, useEditPostMutation } from '@/features/api/apiSlice'
// omit form types
export const EditPostForm = () => {
const { postId } = useParams()
const navigate = useNavigate()
const { data: post } = useGetPostQuery(postId!)
const [updatePost, { isLoading }] = useEditPostMutation()
if (!post) {
return (
<section>
<h2>Post not found!</h2>
</section>
)
}
const onSavePostClicked = async (
e: React.FormEvent<EditPostFormElements>
) => {
// Prevent server submission
e.preventDefault()
const { elements } = e.currentTarget
const title = elements.postTitle.value
const content = elements.postContent.value
if (title && content) {
await updatePost({ id: post.id, title, content })
navigate(`/posts/${postId}`)
}
}
// omit rendering
}
Время жизни подписок на кэшированные данные
Попробуем на практике. Откройте DevTools браузера, перейдите на вкладку Network, обновите страницу, очистите вкладку и войдите в систему. Вы увидите GET запрос к /posts для получения исходных данных. При клике на "Просмотреть пост" появится второй запрос к /posts/:postId, возвращающий конкретный пост.
Теперь нажмите "Редактировать пост" на странице поста. Интерфейс переключится на <EditPostForm>, но сетевого запроса для отдельного поста не будет. Почему?

RTK Query позволяет нескольким компонентам подписываться на одни и те же данные, гарантируя при этом единократную загрузку каждого уникального набора данных. Внутри RTK Query ведёт счётчик активных "подписок" для каждой комбинации эндпоинта и ключа кэша. Если Компонент A вызывает useGetPostQuery(42), данные будут загружены. Если затем Компонент B монтируется и также вызывает useGetPostQuery(42), он запрашивает те же данные. Поскольку запись уже есть в кэше, повторный запрос не выполняется. Оба хука вернут идентичные результаты, включая полученные data и флаги состояния загрузки.
Когда количество активных подписок достигает нуля, RTK Query запускает внутренний таймер. Если до добавления новых подписок таймер истекает, RTK Query автоматически удалит эти данные из кэша, поскольку приложению они больше не нужны. Однако если новая подписка добавляется до истечения таймера, он сбрасывается, а уже закэшированные данные используются без повторного запроса.
В нашем случае <SinglePostPage> смонтировался и запросил конкретный Post по ID. При клике на "Edit Post" компонент <SinglePostPage> размонтировался роутером, и активная подписка была удалена. RTK Query немедленно запустил таймер "удалить данные этого поста". Но компонент <EditPostPage> смонтировался сразу же, подписавшись на те же данные Post с тем же ключом кэша. Поэтому RTK Query отменил таймер и продолжил использовать существующие кэшированные данные вместо запроса к серверу.
По умолчанию неиспользуемые данные удаляются из кэша через 60 секунд, но это поведение можно настроить либо в корневом определении API-среза, либо переопределить для конкретных эндпоинтов через флаг keepUnusedDataFor, указывающий время жизни в секундах.
Инвалидация конкретных записей
Наш компонент <EditPostForm> теперь может сохранять отредактированный пост на сервер, но возникает проблема. После сохранения мы возвращаемся на <SinglePostPage>, который всё ещё показывает старые данные без изменений. <SinglePostPage> продолжает использовать закэшированную запись Post, полученную ранее. Более того, если вернуться на главную страницу к <PostsList>, там также отображаются старые данные. Нам нужен способ принудительно перезапросить как конкретную запись Post, так и весь список постов.
Ранее мы использовали "теги" для инвалидации частей кэшированных данных. Мы объявили, что эндпоинт getPosts предоставляет тег 'Post', а эндпоинт addNewPost инвалидирует тот же тег 'Post'. Благодаря этому при добавлении нового поста RTK Query перезапрашивает весь список через эндпоинт getQuery.
Мы могли бы добавить тег 'Post' и к getPost, и к editPost, но тогда перезапросились бы все остальные посты. К счастью, RTK Query позволяет создавать специфические теги для точечной инвалидации данных, например {type: 'Post', id: 123}.
Наш getPosts содержит поле providesTags в виде массива строк. Но providesTags также может принимать функцию с аргументами result и arg, возвращающую массив тегов. Это позволяет создавать теги на основе ID полученных данных. Аналогично, invalidatesTags тоже может быть функцией.
Для правильного поведения настроим теги для каждого эндпоинта:
-
getPosts: предоставляет общий тег'Post'для всего списка и специфический тег{type: 'Post', id}для каждого полученного объекта поста -
getPost: предоставляет специфический тег{type: 'Post', id}для конкретного объекта поста -
addNewPost: аннулирует общий тег'Post', чтобы перезапросить весь список -
editPost: аннулирует конкретный тег{type: 'Post', id}. Это вызовет перезапрос как отдельного поста черезgetPost, так и всего списка постов черезgetPosts, поскольку оба предоставляют тег, соответствующий этому значению{type, id}.
export const apiSlice = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
tagTypes: ['Post'],
endpoints: builder => ({
getPosts: builder.query<Post[], void>({
query: () => '/posts',
providesTags: (result = [], error, arg) => [
'Post',
...result.map(({ id }) => ({ type: 'Post', id }) as const)
]
}),
getPost: builder.query<Post, string>({
query: postId => `/posts/${postId}`,
providesTags: (result, error, arg) => [{ type: 'Post', id: arg }]
}),
addNewPost: builder.mutation<Post, NewPost>({
query: initialPost => ({
url: '/posts',
method: 'POST',
body: initialPost
}),
invalidatesTags: ['Post']
}),
editPost: builder.mutation<Post, PostUpdate>({
query: post => ({
url: `posts/${post.id}`,
method: 'PATCH',
body: post
}),
invalidatesTags: (result, error, arg) => [{ type: 'Post', id: arg.id }]
})
})
})
Аргумент result в этих колбэках может быть undefined, если ответ не содержит данных или возникла ошибка, поэтому мы должны обрабатывать это безопасно. Для getPosts мы используем значение массива по умолчанию для перебора, а для getPost возвращаем массив из одного элемента на основе ID аргумента. В editPost мы знаем ID поста из частичного объекта, переданного в триггер-функцию, поэтому можем прочитать его оттуда.
С этими изменениями попробуем снова отредактировать пост, открыв вкладку Network в браузерных DevTools.
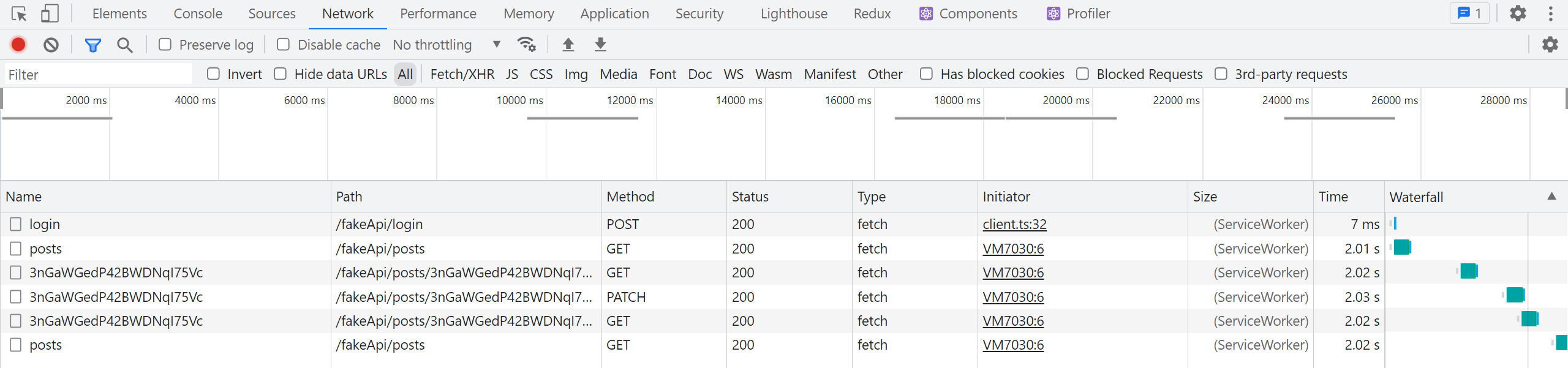
При сохранении изменённого поста теперь мы увидим два последовательных запроса:
-
PATCH /posts/:postIdиз мутацииeditPost -
GET /posts/:postIdпри перезапросеgetPost
Если затем вернуться на вкладку "Posts", мы также увидим:
GET /postsпри перезапросеgetPosts
Благодаря связям между конечными точками через теги, RTK Query автоматически перезапросила отдельный пост и список постов после аннулирования тега с конкретным ID — без дополнительных действий! При этом таймер удаления кэша для данных getPosts истёк во время редактирования, поэтому данные были удалены из кэша. При повторном открытии компонента <PostsList> RTK Query обнаружила отсутствие данных в кэше и выполнила перезапрос.
Есть один нюанс: указание общего тега 'Post' в getPosts и его аннулирование в addNewPost приводит к перезапросу всех отдельных постов. Если нужно перезапросить только список постов для getPosts, можно добавить дополнительный тег с произвольным ID, например {type: 'Post', id: 'LIST'}, и аннулировать именно его. В документации RTK Query есть таблица поведения при аннулировании разных комбинаций тегов.
RTK Query предоставляет множество других опций для управления перезапросом данных, включая "условную загрузку", "ленивые запросы" и "предзагрузку". Определения запросов можно кастомизировать различными способами. Подробнее в документации:
Обновление отображения уведомлений
При переходе с тунков на мутации RTK Query для добавления постов мы случайно сломали отображение уведомления "New post added", поскольку экшен addNewPost.fulfilled больше не диспатчится.
К счастью, это легко исправить. RTK Query внутри использует createAsyncThunk, и мы уже видели, что он диспатчит Redux-экшены по мере выполнения запросов. Мы можем обновить обработчик тостов, чтобы он отслеживал внутренние экшены RTKQ и показывал тост при их возникновении.
createApi автоматически генерирует санки для каждого эндпоинта. Он также создает RTK "матчер-функции", которые принимают объект экшена и возвращают true, если экшен соответствует условию. Эти матчеры можно использовать везде, где нужно проверить соответствие экшена условию, например внутри startAppListening. Они также работают как TypeScript type guards, сужая тип объекта action для безопасного доступа к его полям.
Сейчас обработчик тостов отслеживает конкретный тип экшена через actionCreator: addNewPost.fulfilled. Мы обновим его для отслеживания добавления постов с помощью matcher: apiSlice.endpoints.addNewPost.matchFulfilled:
import { createEntityAdapter, createSelector, createSlice, EntityState, PayloadAction } from '@reduxjs/toolkit'
import { client } from '@/api/client'
import type { RootState } from '@/app/store'
import { AppStartListening } from '@/app/listenerMiddleware'
import { createAppAsyncThunk } from '@/app/withTypes'
import { apiSlice } from '@/features/api/apiSlice'
import { logout } from '@/features/auth/authSlice'
// omit types, posts slice, and selectors
export const addPostsListeners = (startAppListening: AppStartListening) => {
startAppListening({
matcher: apiSlice.endpoints.addNewPost.matchFulfilled,
effect: async (action, listenerApi) => {
Теперь тост должен снова корректно появляться при добавлении поста.
Управление данными пользователей
Мы завершили переход на RTK Query для управления данными постов. Далее мы переведем список пользователей.
Поскольку мы уже видели использование хуков RTK Query для получения и чтения данных, в этом разделе мы попробуем другой подход. Как и остальная часть Redux Toolkit, основная логика RTK Query не зависит от UI и может использоваться с любым слоем представления, не только с React.
Обычно следует использовать React-хуки, генерируемые createApi, так как они выполняют много работы за вас. Но для демонстрации мы будем работать с данными пользователей, используя только базовый API RTK Query, чтобы показать, как это работает.
Ручное получение пользователей
Сейчас мы определяем асинхронный санк fetchUsers в usersSlice.ts и диспатчим его вручную в main.tsx, чтобы список пользователей был доступен как можно раньше. Мы можем повторить этот процесс с помощью RTK Query.
Начнем с определения query-эндпоинта getUsers в apiSlice.ts, аналогично существующим эндпоинтам. Мы экспортируем хук useGetUsersQuery для согласованности, но пока не будем его использовать.
import { createApi, fetchBaseQuery } from '@reduxjs/toolkit/query/react'
import type { Post, NewPost, PostUpdate } from '@/features/posts/postsSlice'
import type { User } from '@/features/users/usersSlice'
export type { Post }
export const apiSlice = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
tagTypes: ['Post'],
endpoints: builder => ({
// omit other endpoints
getUsers: builder.query<User[], void>({
query: () => '/users'
})
})
})
export const {
useGetPostsQuery,
useGetPostQuery,
useGetUsersQuery,
useAddNewPostMutation,
useEditPostMutation
} = apiSlice
Если мы посмотрим на объект API-среза, он включает поле endpoints с объектом эндпоинта для каждого определённого нами эндпоинта.

Каждый объект эндпоинта содержит:
-
Основной хук для запросов/мутаций, который мы экспортируем из корневого объекта API, но под именем
useQueryилиuseMutation -
Для query-эндпоинтов — дополнительные хуки для сценариев типа "ленивых запросов" или частичных подписок
-
Набор утилит-"матчеров" для проверки экшенов
pending/fulfilled/rejected, диспатчимых запросами для этого эндпоинта -
Санк
initiate, который запускает запрос для этого эндпоинта -
Функцию
select, создающую мемоизированные селекторы для получения кэшированных данных и статусов для этого эндпоинта
Если мы хотим получить список пользователей вне React, мы можем диспатчить санк getUsers.initiate() в нашем index-файле:
// omit other imports
import { apiSlice } from './features/api/apiSlice'
async function main() {
// Start our mock API server
await worker.start({ onUnhandledRequest: 'bypass' })
store.dispatch(apiSlice.endpoints.getUsers.initiate())
const root = createRoot(document.getElementById('root')!)
root.render(
<React.StrictMode>
<Provider store={store}>
<App />
</Provider>
</React.StrictMode>
)
}
main()
Этот диспатч автоматически происходит внутри query-хуков, но мы можем запустить его вручную при необходимости, вызвав санк initiate.
Обратите внимание, что мы не передали аргумент в initiate(). Это связано с тем, что наш эндпоинт getUsers не требует специфического аргумента запроса. Концептуально это эквивалентно утверждению «эта запись кеша имеет аргумент запроса undefined». Если бы аргументы были нужны, мы бы передали их в санк, например: dispatch(apiSlice.endpoints.getPokemon.initiate('pikachu')).
В данном случае мы вручную диспатчим санк для предварительной загрузки данных в функции инициализации приложения. На практике вы можете выполнять предзагрузку в «data loaders» React Router, чтобы запускать запросы до рендеринга компонентов. (Идеи можно почерпнуть в обсуждении лоадеров React Router в репозитории RTK.)
Ручной диспатч санка запроса RTKQ создаёт подписку, но затем вам нужно отписаться от этих данных — иначе данные останутся в кеше навсегда. В нашем случае данные пользователей нужны постоянно, поэтому отписку можно пропустить.
Выбор данных о пользователях
Сейчас у нас есть селекторы вроде selectAllUsers и selectUserById, сгенерированные адаптером createEntityAdapter для пользователей и читающие из state.users. При перезагрузке страницы все элементы интерфейса, связанные с пользователями, перестанут работать, поскольку слайс state.users пуст. Теперь, когда данные загружаются в кеш RTK Query, нам следует заменить эти селекторы эквивалентами, читающими из кеша.
Функция endpoint.select() в эндпоинтах API-слайса создаёт новый мемоизированный селектор при каждом вызове. select() принимает ключ кеша как аргумент, который должен совпадать с ключом, передаваемым в хуки запросов или санк initiate(). Созданный селектор использует этот ключ для точного определения возвращаемой записи кеша из состояния хранилища.
В нашем случае эндпоинту getUsers не нужны параметры — мы всегда получаем полный список пользователей. Поэтому можно создать селектор кеша без аргумента (эквивалентно передаче ключа undefined).
Обновим usersSlice.ts, чтобы селекторы основывались на кеше запросов RTKQ вместо вызова usersSlice:
import {
createEntityAdapter,
createSelector,
createSlice
} from '@reduxjs/toolkit'
import { client } from '@/api/client'
import type { RootState } from '@/app/store'
import { createAppAsyncThunk } from '@/app/withTypes'
import { apiSlice } from '@/features/api/apiSlice'
import { selectCurrentUsername } from '@/features/auth/authSlice'
export interface User {
id: string
name: string
}
// omit `fetchUsers` and `usersSlice`
const emptyUsers: User[] = []
// Calling `someEndpoint.select(someArg)` generates a new selector that will return
// the query result object for a query with those parameters.
// To generate a selector for a specific query argument, call `select(theQueryArg)`.
// In this case, the users query has no params, so we don't pass anything to select()
export const selectUsersResult = apiSlice.endpoints.getUsers.select()
export const selectAllUsers = createSelector(
selectUsersResult,
usersResult => usersResult?.data ?? emptyUsers
)
export const selectUserById = createSelector(
selectAllUsers,
(state: RootState, userId: string) => userId,
(users, userId) => users.find(user => user.id === userId)
)
export const selectCurrentUser = (state: RootState) => {
const currentUsername = selectCurrentUsername(state)
if (currentUsername) {
return selectUserById(state, currentUsername)
}
}
/* Temporarily ignore adapter selectors - we'll come back to this later
export const { selectAll: selectAllUsers, selectById: selectUserById } = usersAdapter.getSelectors(
(state: RootState) => state.users,
)
*/
Начнём с создания конкретного экземпляра селектора selectUsersResult, который умеет извлекать нужную запись кеша.
Получив начальный селектор selectUsersResult, мы заменим существующий selectAllUsers на селектор, возвращающий массив пользователей из результата кеша. На случай отсутствия валидных данных добавим откат к пустому массиву emptyUsers. Также заменим selectUserById на селектор, находящий нужного пользователя в этом массиве.
Пока закомментируем эти селекторы в usersAdapter — позже мы внесём изменения, возвращающие их использование.
Наши компоненты уже импортируют selectAllUsers, selectUserById и selectCurrentUser, поэтому изменения должны работать сразу! Попробуйте обновить страницу и перейти между списком постов и страницей отдельного поста. Имена пользователей должны корректно отображаться в каждом посте и в выпадающем списке <AddPostForm>.
Это отличный пример поддерживаемости кода благодаря селекторам! Компоненты уже использовали эти селекторы, поэтому их не волнует источник данных (существующее состояние usersSlice или запись кеша RTK Query), главное — соответствие ожидаемому формату. Мы изменили реализации селекторов без правки UI-компонентов.
Поскольку состояние usersSlice вообще больше не используется, мы можем удалить вызов const usersSlice = createSlice() и тунк fetchUsers из этого файла, а также убрать users: usersReducer из настройки хранилища. У нас всё ещё остаются некоторые части кода, ссылающиеся на postsSlice, поэтому мы пока не можем полностью удалить их — мы вернёмся к этому позже.
Разделение и внедрение конечных точек
Мы говорили, что в RTK Query обычно используется один "API слой" на приложение, и до сих пор все наши эндпоинты определялись непосредственно в apiSlice.ts. Однако в крупных приложениях часто применяется "разделение кода" (code-splitting) для выноса функциональности в отдельные бандлы с последующей "ленивой загрузкой" (lazy loading) по мере необходимости при первом использовании функции. Что делать, если мы хотим разделить некоторые определения эндпоинтов или перенести их в другой файл, чтобы избежать разрастания API слоя?
RTK Query поддерживает разделение определений конечных точек через apiSlice.injectEndpoints(). Так мы сохраняем единый экземпляр API среза с одним middleware и редюсером кэша, но можем выносить определения части конечных точек в другие файлы. Это позволяет реализовать сценарии разделения кода, а также при необходимости размещать конечные точки рядом с соответствующими функциональными модулями.
Чтобы продемонстрировать этот подход, перенесём конечную точку getUsers из apiSlice.ts в usersSlice.ts, внедрив её через инъекцию.
Мы уже импортируем apiSlice в usersSlice.ts для доступа к конечной точке getUsers, поэтому можем заменить это вызовом apiSlice.injectEndpoints().
import { apiSlice } from '../api/apiSlice'
// This is the _same_ reference as `apiSlice`, but this has
// the TS types updated to include the injected endpoints
export const apiSliceWithUsers = apiSlice.injectEndpoints({
endpoints: builder => ({
getUsers: builder.query<User[], void>({
query: () => '/users'
})
})
})
export const { useGetUsersQuery } = apiSliceWithUsers
export const selectUsersResult = apiSliceWithUsers.endpoints.getUsers.select()
injectEndpoints() мутирует исходный объект API среза, добавляя новые определения конечных точек, и возвращает тот же экземпляр API. Кроме того, возвращаемое значение injectEndpoints включает дополнительные TypeScript-типы из внедрённых конечных точек.
Из-за этого следует сохранить результат в новую переменную с другим именем, чтобы использовать обновлённые TS-типы, обеспечить корректную компиляцию и явно указывать используемую версию API среза. Здесь мы назовём её apiSliceWithUsers для отличия от исходного apiSlice.
Сейчас единственный файл, использующий конечную точку getUsers, — это точка входа, которая диспатчит тунк initiate. Нужно обновить импорт, чтобы использовать расширенный API срез:
import { apiSliceWithUsers } from './features/users/usersSlice'
import { worker } from './api/server'
import './index.css'
// Wrap app rendering so we can wait for the mock API to initialize
async function start() {
// Start our mock API server
await worker.start({ onUnhandledRequest: 'bypass' })
store.dispatch(apiSliceWithUsers.endpoints.getUsers.initiate())
const root = createRoot(document.getElementById('root')!)
root.render(
<React.StrictMode>
<Provider store={store}>
<App />
</Provider>
</React.StrictMode>
)
}
Альтернативно можно экспортировать сами конечные точки из файла среза, аналогично тому, как мы экспортируем создатели действий (action creators) в срезах.
Манипулирование данными ответа
До сих пор все наши конечные точки запроса сохраняли данные ответа сервера в кэше "как есть" — в том виде, в котором они были получены в теле. getPosts и getUsers ожидают от сервера массив, а getPost — отдельный объект Post.
Часто клиентам требуется извлекать фрагменты данных из ответа сервера или трансформировать их перед кэшированием. Например, что если запрос /getPost возвращает тело вида {post: {id}} с вложенными данными?
Концептуально есть несколько подходов к решению. Один вариант — извлечь поле responseData.post и сохранить в кэше только его вместо всего тела. Другой — сохранять полный ответ, но позволить компонентам запрашивать только нужные части кэшированных данных.
Трансформация ответов
Конечные точки могут определять обработчик transformResponse для извлечения или модификации данных сервера перед кэшированием. Например, если getPost возвращает {post: {id}}, можно задать transformResponse: (responseData) => responseData.post, что сохранит в кэше непосредственно объект Post, а не всё тело ответа.
В Части 6: Производительность и нормализация мы обсуждали, почему полезно хранить данные в нормализованной структуре. В частности, это позволяет нам находить и обновлять элементы по ID, вместо перебора всего массива для поиска нужного элемента.
В настоящее время наш селектор selectUserById вынужден перебирать кешированный массив пользователей, чтобы найти нужный объект User. Если бы мы преобразовали ответ в нормализованную структуру, мы могли бы упростить этот процесс до прямого поиска пользователя по ID.
Ранее мы использовали createEntityAdapter в usersSlice для управления нормализованными данными пользователей. Мы можем интегрировать createEntityAdapter в наш extendedApiSlice, фактически используя createEntityAdapter для преобразования данных перед кешированием. Мы раскомментируем изначально присутствовавшие строки с usersAdapter и снова будем использовать его функции обновления и селекторы.
import {
createSelector,
createEntityAdapter,
EntityState
} from '@reduxjs/toolkit'
import type { RootState } from '@/app/store'
import { apiSlice } from '@/features/api/apiSlice'
import { selectCurrentUsername } from '@/features/auth/authSlice'
export interface User {
id: string
name: string
}
const usersAdapter = createEntityAdapter<User>()
const initialState = usersAdapter.getInitialState()
// This is the _same_ reference as `apiSlice`, but this has
// the TS types updated to include the injected endpoints
export const apiSliceWithUsers = apiSlice.injectEndpoints({
endpoints: builder => ({
getUsers: builder.query<EntityState<User, string>, void>({
query: () => '/users',
transformResponse(res: User[]) {
// Create a normalized state object containing all the user items
return usersAdapter.setAll(initialState, res)
}
})
})
})
export const { useGetUsersQuery } = apiSliceWithUsers
// Calling `someEndpoint.select(someArg)` generates a new selector that will return
// the query result object for a query with those parameters.
// To generate a selector for a specific query argument, call `select(theQueryArg)`.
// In this case, the users query has no params, so we don't pass anything to select()
export const selectUsersResult = apiSliceWithUsers.endpoints.getUsers.select()
const selectUsersData = createSelector(
selectUsersResult,
// Fall back to the empty entity state if no response yet.
result => result.data ?? initialState
)
export const selectCurrentUser = (state: RootState) => {
const currentUsername = selectCurrentUsername(state)
if (currentUsername) {
return selectUserById(state, currentUsername)
}
}
export const { selectAll: selectAllUsers, selectById: selectUserById } =
usersAdapter.getSelectors(selectUsersData)
Мы добавили опцию transformResponse в эндпоинт getUsers. Она получает всё тело ответа (в данном случае массив User[]) и должна вернуть фактические данные для кеширования. Вызов usersAdapter.setAll(initialState, responseData) возвращает стандартную нормализованную структуру {ids: [], entities: {}}, содержащую все полученные элементы. Нам нужно указать TypeScript, что теперь мы возвращаем именно эти данные EntityState<User, string> как содержимое поля data в кеше.
Функции adapter.getSelectors() требуется "входной селектор", чтобы она понимала, где искать нормализованные данные. В данном случае данные вложены в кеш-редюсер RTK Query, поэтому мы выбираем нужное поле из состояния кеша. Для единообразия мы можем создать селектор selectUsersData, который возвращает начальное пустое нормализованное состояние, если данные ещё не были получены.
Нормализованный vs Документный кеш
Стоит сделать шаг назад и обсудить, что мы только что сделали и почему это важно.
Вы могли слышать термин "нормализованный кеш" в контексте других библиотек для работы с данными, например Apollo. Важно понимать, что RTK Query использует подход "документного кеша", а не "нормализованного кеша".
Полностью нормализованный кеш пытается дедуплицировать похожие элементы во всех запросах на основе типа элемента и его ID. Например, допустим у нас есть API-слайс с эндпоинтами getTodos и getTodo, а компоненты выполняют следующие запросы:
-
getTodos() -
getTodos({filter: 'odd'}) -
getTodo({id: 1})
Каждый из этих результатов запроса будет включать объект Todo вида {id: 1}.
В полностью нормализованном дедуплицирующем кеше хранилась бы только одна копия этого объекта Todo. Однако RTK Query сохраняет каждый результат запроса независимо в кеше. Таким образом, в Redux-сторе будут закешированы три отдельные копии этого Todo. Тем не менее, если все эндпоинты последовательно предоставляют одинаковые теги (например {type: 'Todo', id: 1}), то инвалидация такого тега заставит все соответствующие эндпоинты перезапросить данные для обеспечения согласованности.
RTK Query намеренно не реализует кеш, который бы дедуплицировал идентичные элементы в разных запросах. На это есть несколько причин:
-
Полностью нормализованный кеш, общий для всех запросов — это сложная задача
-
У нас нет времени, ресурсов или желания решать её в данный момент
-
Во многих случаях простой перезапрос данных при их инвалидации работает хорошо и проще для понимания
-
Главная цель RTKQ — помочь решить типичную задачу "получить какие-то данные", которая является большой проблемой для многих разработчиков
В данном случае мы просто нормализовали данные ответа для эндпоинта getUsers, сохранив их в виде таблицы поиска {[id]: value}. Однако это не то же самое, что "нормализованный кэш" — мы лишь преобразовали способ хранения этого конкретного ответа, а не занимались дедупликацией результатов между эндпоинтами или запросами.
Выбор значений из результатов
Последний компонент, который читает данные из старого postsSlice — это <UserPage>, фильтрующий список постов по текущему пользователю. Мы уже видели, что можем получить весь список постов через useGetPostsQuery() и преобразовать его в компоненте, например отсортировав через useMemo. Хуки запросов также позволяют выбирать фрагменты кэшированного состояния с помощью опции selectFromResult, перерисовывая компонент только при изменении выбранных данных.
Хуки useQuery всегда принимают ключ кэша первым параметром, а если нужно передать опции — они всегда идут вторым параметром: useSomeQuery(cacheKey, options). Для эндпоинта getUsers нет фактического ключа кэша. Семантически это эквивалентно ключу undefined. Поэтому для передачи опций мы должны вызвать useGetUsersQuery(undefined, options).
Мы можем использовать selectFromResult, чтобы <UserPage> читал из кэша только отфильтрованный список постов. Однако для предотвращения лишних перерисовок selectFromResult должен гарантировать мемоизацию извлекаемых данных. Для этого создаём новый экземпляр селектора, который компонент <UserPage> сможет переиспользовать при каждом рендере — так селектор будет мемоизировать результат на основе входных данных.
import { Link, useParams } from 'react-router-dom'
import { createSelector } from '@reduxjs/toolkit'
import type { TypedUseQueryStateResult } from '@reduxjs/toolkit/query/react'
import { useAppSelector } from '@/app/hooks'
import { useGetPostsQuery, Post } from '@/features/api/apiSlice'
import { selectUserById } from './usersSlice'
// Create a TS type that represents "the result value passed
// into the `selectFromResult` function for this hook"
type GetPostsSelectFromResultArg = TypedUseQueryStateResult<Post[], any, any>
const selectPostsForUser = createSelector(
(res: GetPostsSelectFromResultArg) => res.data,
(res: GetPostsSelectFromResultArg, userId: string) => userId,
(data, userId) => data?.filter(post => post.user === userId)
)
export const UserPage = () => {
const { userId } = useParams()
const user = useAppSelector(state => selectUserById(state, userId!))
// Use the same posts query, but extract only part of its data
const { postsForUser } = useGetPostsQuery(undefined, {
selectFromResult: result => ({
// Optional: Include all of the existing result fields like `isFetching`
...result,
// Include a field called `postsForUser` in the result object,
// which will be a filtered list of posts
postsForUser: selectPostsForUser(result, userId!)
})
})
// omit rendering logic
}
Ключевое отличие созданного мемоизированного селектора: обычно селекторы ожидают весь Redux state первым аргументом и извлекают/вычисляют значение из state. Здесь же мы работаем только со значением "результата", хранящимся в кэше. Объект результата содержит поле data с актуальными значениями и метаданные запроса.
Поскольку этот селектор получает не стандартный RootState, а другой тип, нужно указать TS структуру результата. RTK Query экспортирует тип TypedUseQueryStateResult, представляющий "объект возврата хука useQuery". Используем его для объявления ожидаемого результата с массивом Post[], затем определяем селектор на его основе.
Начиная с RTK 2.x и Reselect 5.x, мемоизированные селекторы имеют неограниченный размер кэша, поэтому смена аргументов сохраняет предыдущие результаты. Если вы используете RTK 1.x или Reselect 4.x, учтите что их селекторы по умолчанию кэшируют только последний вызов. Вам потребуется создавать уникальный экземпляр селектора для каждого компонента для корректной мемоизации при разных аргументах (например ID).
Наш колбэк selectFromResult получает объект result с метаданными запроса и серверными data, возвращая извлечённые/вычисленные значения. Поскольку хуки запросов добавляют метод refetch к возвращаемым данным, selectFromResult всегда должен возвращать объект с нужными полями.
Объект result хранится в Redux-сторе, поэтому его нельзя мутировать — возвращаем новый объект. Хук сделает поверхностное сравнение возвращённого объекта и перерисует компонент только при изменении одного из полей. Мы можем оптимизировать перерисовки, возвращая только специфичные поля — если метаданные не нужны, их можно опустить. При необходимости — распакуйте исходный result через спред оператор.
В этом случае мы назовём поле postsForUser и сможем деструктурировать это новое поле из результата хука. Вызывая selectPostsForUser(result, userId) каждый раз, мы мемоизируем отфильтрованный массив и пересчитываем его только при изменении полученных данных или ID пользователя.
Сравнение подходов к трансформации данных
Мы рассмотрели три различных способа управления трансформацией ответов:
-
Хранение исходного ответа в кэше, чтение полного результата в компоненте и вычисление производных значений
-
Хранение исходного ответа в кэше, чтение производного результата через
selectFromResult -
Трансформация ответа перед сохранением в кэше
Каждый из этих подходов может быть полезен в разных ситуациях. Вот рекомендации по их применению:
-
transformResponse: все потребители конечной точки требуют определённого формата, например нормализации ответа для ускорения поиска по ID -
selectFromResult: некоторые потребители конечной точки нуждаются только в частичных данных, например в отфильтрованном списке -
На уровне компонента /
useMemo: когда только определённые компоненты нуждаются в трансформации кэшированных данных
Продвинутое управление кэшем
Мы завершили обновление данных постов и пользователей, осталось поработать с реакциями и уведомлениями. Переход на RTK Query даст возможность опробовать продвинутые техники работы с кэшем и улучшить пользовательский опыт.
Сохранение реакций
Изначально мы отслеживали реакции только на клиентской стороне без сохранения на сервере. Добавим новую мутацию addReaction для обновления соответствующего Post на сервере при каждом клике по кнопке реакции.
export const apiSlice = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
tagTypes: ['Post'],
endpoints: builder => ({
// omit other endpoints
addReaction: builder.mutation<
Post,
{ postId: string; reaction: ReactionName }
>({
query: ({ postId, reaction }) => ({
url: `posts/${postId}/reactions`,
method: 'POST',
// In a real app, we'd probably need to base this on user ID somehow
// so that a user can't do the same reaction more than once
body: { reaction }
}),
invalidatesTags: (result, error, arg) => [
{ type: 'Post', id: arg.postId }
]
})
})
})
export const {
useGetPostsQuery,
useGetPostQuery,
useAddNewPostMutation,
useEditPostMutation,
useAddReactionMutation
} = apiSlice
Как и в других мутациях, мы принимаем параметры и отправляем запрос на сервер с данными в теле. Для нашего примера просто передадим название реакции, позволяя серверу увеличить счётчик этого типа реакции для поста.
Нам известно, что для отображения изменений данных на клиенте нужно перезапросить этот пост, поэтому мы можем инвалидировать конкретную запись Post по её ID.
Обновим компонент <ReactionButtons> для использования этой мутации.
import { useAddReactionMutation } from '@/features/api/apiSlice'
import type { Post, ReactionName } from './postsSlice'
const reactionEmoji: Record<ReactionName, string> = {
thumbsUp: '👍',
tada: '🎉',
heart: '❤️',
rocket: '🚀',
eyes: '👀'
}
interface ReactionButtonsProps {
post: Post
}
export const ReactionButtons = ({ post }: ReactionButtonsProps) => {
const [addReaction] = useAddReactionMutation()
const reactionButtons = Object.entries(reactionEmoji).map(
([stringName, emoji]) => {
// Ensure TS knows this is a _specific_ string type
const reaction = stringName as ReactionName
return (
<button
key={reaction}
type="button"
className="muted-button reaction-button"
onClick={() => {
addReaction({ postId: post.id, reaction })
}}
>
{emoji} {post.reactions[reaction]}
</button>
)
}
)
return <div>{reactionButtons}</div>
}
Проверим в действии! Перейдём к списку постов <PostsList> и кликнем по одной из реакций.
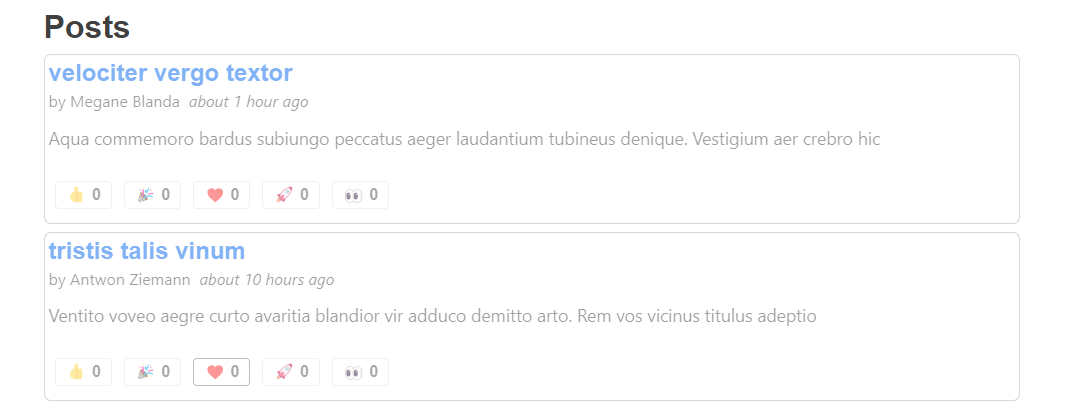
Ой! Весь компонент <PostsList> стал неактивным, потому что мы перезапросили весь список постов из-за обновления одного поста. Это особенно заметно из-за искусственной задержки в 2 секунды у нашего mock-сервера, но даже при быстром ответе такой пользовательский опыт нежелателен.
Оптимистичное обновление реакций
Для мелких обновлений вроде добавления реакции перезапрос всего списка постов избыточен. Вместо этого мы можем обновить уже кэшированные данные на клиенте в соответствии с ожидаемыми изменениями на сервере. При мгновенном обновлении кэша пользователь получает обратную связь сразу при клике без ожидания ответа сервера. Такой подход к немедленному обновлению клиентского состояния называется "оптимистичное обновление" и широко применяется в веб-приложениях.
RTK Query предоставляет утилиты для прямого обновления клиентского кэша. Их можно комбинировать с методами жизненного цикла запросов для реализации оптимистичных обновлений.
Утилиты обновления кэша
API-срезы содержат дополнительные методы, доступные через api.util. Сюда входят санки для модификации кэша: upsertQueryData для добавления или замены записи кэша и updateQueryData для изменения существующей записи. Поскольку это санки, их можно использовать везде, где доступен dispatch.
В частности, утилита updateQueryData принимает три аргумента: имя обновляемого эндпоинта, ключ кэша (такой же, как для идентификации конкретной записи), и колбэк для изменения кэшированных данных. updateQueryData использует Immer, поэтому вы можете "мутировать" данные в черновике кэша так же, как в createSlice:
dispatch(
apiSlice.util.updateQueryData(endpointName, queryArg, draft => {
// mutate `draft` here like you would in a reducer
draft.value = 123
})
)
updateQueryData генерирует объект экшена с патч-разницей изменений. При dispatch этого экшна возвращаемое значение — объект patchResult. Если вызвать patchResult.undo(), автоматически отправится экшен, отменяющий изменения патча.
Жизненный цикл onQueryStarted
Первый рассматриваемый метод жизненного цикла — onQueryStarted. Эта опция доступна для запросов и мутаций.
При его наличии onQueryStarted будет вызываться при каждом новом запросе. Это позволяет запускать дополнительную логику в ответ на запрос.
Как и в асинхронных санках и эффектах слушателей, колбэк onQueryStarted получает значение arg запроса первым аргументом и объект lifecycleApi вторым. lifecycleApi содержит те же поля {dispatch, getState, extra, requestId}, что и createAsyncThunk. Дополнительно в нём есть уникальные поля, из которых наиболее важное — lifecycleApi.queryFulfilled, промис, разрешающийся при возврате запроса (с успехом или ошибкой).
Реализация оптимистичных обновлений
Используя утилиты обновления внутри onQueryStarted, можно реализовать либо оптимистичные обновления (изменение кэша до завершения запроса), либо пессимистичные (изменение кэша после завершения запроса).
Оптимистичное обновление реализуется поиском конкретной записи Post в кэше getPosts и её "мутацией" для увеличения счётчика реакций. Если существует дублирующая запись того же Post в кэше getPost, её также нужно обновить.
По умолчанию предполагается успешный запрос. При ошибке можно await lifecycleApi.queryFulfilled, перехватить сбой и отменить патч-изменения для отката оптимистичного обновления.
export const apiSlice = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
tagTypes: ['Post'],
endpoints: builder => ({
// omit other endpoints
addReaction: builder.mutation<
Post,
{ postId: string; reaction: ReactionName }
>({
query: ({ postId, reaction }) => ({
url: `posts/${postId}/reactions`,
method: 'POST',
// In a real app, we'd probably need to base this on user ID somehow
// so that a user can't do the same reaction more than once
body: { reaction }
}),
// The `invalidatesTags` line has been removed,
// since we're now doing optimistic updates
async onQueryStarted({ postId, reaction }, lifecycleApi) {
// `updateQueryData` requires the endpoint name and cache key arguments,
// so it knows which piece of cache state to update
const getPostsPatchResult = lifecycleApi.dispatch(
apiSlice.util.updateQueryData('getPosts', undefined, draft => {
// The `draft` is Immer-wrapped and can be "mutated" like in createSlice
const post = draft.find(post => post.id === postId)
if (post) {
post.reactions[reaction]++
}
})
)
// We also have another copy of the same data in the `getPost` cache
// entry for this post ID, so we need to update that as well
const getPostPatchResult = lifecycleApi.dispatch(
apiSlice.util.updateQueryData('getPost', postId, draft => {
draft.reactions[reaction]++
})
)
try {
await lifecycleApi.queryFulfilled
} catch {
getPostsPatchResult.undo()
getPostPatchResult.undo()
}
}
})
})
})
В данном случае мы также удалили строку invalidatesTags, добавленную ранее, поскольку нам не нужно перезапрашивать посты при клике на кнопку реакции.
Теперь при быстрых кликах на кнопку реакции в UI будет видно увеличение числа. В Network-вкладке также будут видны отдельные запросы к серверу.
Иногда мутационные запросы возвращают полезные данные в ответе сервера (например, окончательный ID элемента вместо временного клиентского ID). Если сначала выполнить const res = await lifecycleApi.queryFulfilled, можно использовать данные ответа для применения пессимистичных обновлений кэша.
Потоковые обновления для уведомлений
Последняя функция — вкладка уведомлений. Когда мы впервые реализовали её в Части 6, мы отметили, что «в реальном приложении сервер отправлял бы обновления клиенту при каждом событии». Изначально мы сымитировали эту функцию кнопкой «Обновить уведомления», которая выполняла HTTP-запрос GET для получения новых записей.
Обычно приложения делают начальный запрос для получения данных с сервера, а затем открывают Websocket-соединение для получения последующих обновлений. Методы жизненного цикла RTK Query позволяют реализовать такие «потоковые обновления» кешированных данных.
Мы уже видели метод onQueryStarted, который использовали для оптимистичных (или пессимистичных) обновлений. Дополнительно RTK Query предоставляет обработчик жизненного цикла onCacheEntryAdded, идеально подходящий для потоковых обновлений. С его помощью мы реализуем более реалистичный подход к управлению уведомлениями.
Жизненный цикл onCacheEntryAdded
Как и onQueryStarted, метод onCacheEntryAdded доступен для запросов и мутаций.
onCacheEntryAdded вызывается при каждом добавлении новой записи кеша (эндпоинт + сериализованные аргументы запроса). Это означает, что он выполняется реже, чем onQueryStarted, который запускается при каждом запросе.
Аналогично onQueryStarted, onCacheEntryAdded получает два параметра. Первый — это обычное значение аргументов запроса (args). Второй — это немного отличающийся lifecycleApi, содержащий {dispatch, getState, extra, requestId}, а также утилиту updateCachedData — альтернативную форму api.util.updateQueryData, которая уже знает правильное имя конечной точки и аргументы запроса для использования и выполняет диспетчеризацию за вас.
Также доступны два дополнительных промиса:
-
cacheDataLoaded: разрешается при получении первого кешированного значения, обычно используется для ожидания фактических данных перед выполнением логики. -
cacheEntryRemoved: выполняется при удалении записи кэша (т.е. когда у неё больше нет подписчиков и запись была удалена сборщиком мусора)
Пока активен хотя бы один подписчик, запись кеша сохраняется. Когда число подписчиков достигает нуля и истекает время жизни кеша, запись удаляется, и cacheEntryRemoved разрешается. Типичный шаблон использования:
-
Немедленно вызвать
await cacheDataLoaded -
Создать подписку на серверные данные (например, Websocket)
- При получении обновления использовать
updateCachedDataдля «мутации» кешированных данных на основе полученного обновления
-
Вызвать
await cacheEntryRemovedв конце -
Выполнить очистку подписок
Это делает onCacheEntryAdded идеальным местом для долгоиграющей логики, которая должна работать, пока UI нуждается в данных. Пример: чат-приложение, которое получает начальные сообщения канала через Websocket и отключает его при закрытии канала пользователем.
Получение уведомлений
Разделим работу на этапы:
Сначала создадим эндпоинт для уведомлений и заменим тунк fetchNotificationsWebsocket, чтобы он инициировал отправку уведомлений через Websocket вместо HTTP-запроса.
Внедрим эндпоинт getNotifications в notificationsSlice по аналогии с getUsers, чтобы продемонстрировать возможность.
import { createEntityAdapter, createSlice } from '@reduxjs/toolkit'
import { client } from '@/api/client'
import { forceGenerateNotifications } from '@/api/server'
import type { AppThunk, RootState } from '@/app/store'
import { createAppAsyncThunk } from '@/app/withTypes'
import { apiSlice } from '@/features/api/apiSlice'
// omit types and `fetchNotifications` thunk
export const apiSliceWithNotifications = apiSlice.injectEndpoints({
endpoints: builder => ({
getNotifications: builder.query<ServerNotification[], void>({
query: () => '/notifications'
})
})
})
export const { useGetNotificationsQuery } = apiSliceWithNotifications
getNotifications — стандартный эндпоинт запроса, хранящий объекты ServerNotification, полученные с сервера.
Затем в компоненте <Navbar> мы можем использовать новый хук запроса для автоматической загрузки уведомлений. Однако сейчас мы получаем только объекты ServerNotification, а не ClientNotification с дополнительными полями {read, isNew}, поэтому временно отключим проверку notification.new:
// omit other imports
import { allNotificationsRead, useGetNotificationsQuery } from './notificationsSlice'
export const NotificationsList = () => {
const dispatch = useAppDispatch()
const { data: notifications = [] } = useGetNotificationsQuery()
useLayoutEffect(() => {
dispatch(allNotificationsRead())
})
const renderedNotifications = notifications.map((notification) => {
const notificationClassname = classnames('notification', {
// new: notification.isNew,
})
}
// omit rendering
}
Если перейти во вкладку "Уведомления", мы увидим несколько записей, но ни одна не будет выделена цветом как новая. При этом при нажатии кнопки "Обновить уведомления" счётчик непрочитанных продолжит увеличиваться. Это происходит по двум причинам: кнопка всё ещё запускает оригинальный thunk fetchNotifications, сохраняющий записи в слайсе state.notifications. Кроме того, компонент <NotificationsList> не перерисовывается (он использует кэшированные данные из хука useGetNotificationsQuery, а не слайс state.notifications), поэтому useLayoutEffect не срабатывает и не диспатчит allNotificationsRead.
Отслеживание состояния на стороне клиента
Следующий шаг — переосмыслить, как мы отслеживаем статус "прочитано" для уведомлений.
Ранее мы брали объекты ServerNotification, полученные через thunk fetchNotifications, добавляли поля {read, isNew} в редюсере и сохраняли их. Теперь же мы сохраняем объекты ServerNotification в кэше RTK Query.
Мы могли бы делать больше ручных обновлений кэша: использовать transformResponse для добавления полей, затем модифицировать сам кэш при просмотре уведомлений пользователем.
Вместо этого мы попробуем другой подход, похожий на предыдущий: будем отслеживать статус прочтения внутри notificationsSlice.
Концептуально нам нужно отслеживать статус {read, isNew} для каждого уведомления. Мы могли бы делать это в слайсе, храня "метаданные" для каждого полученного уведомления, если бы у нас был доступ к ID уведомлений при получении их через хук запроса.
К счастью, это возможно! Поскольку RTK Query построен на стандартных инструментах Redux Toolkit вроде createAsyncThunk, он диспатчит действие fulfilled с результатами после каждого запроса. Нам просто нужно прослушивать это действие в notificationsSlice через createSlice.extraReducers.
Но какое именно действие слушать? Поскольку это эндпоинт RTKQ, у нас нет прямого доступа к генераторам действий asyncThunk.fulfilled/pending, поэтому мы не можем просто передать их в builder.addCase().
Эндпоинты RTK Query предоставляют функцию-матчер matchFulfilled, которую можно использовать в extraReducers для прослушивания действий fulfilled этого эндпоинта. (Обратите внимание, что вместо builder.addCase() нужно использовать builder.addMatcher()).
Итак, мы заменим ClientNotification на новый тип NotificationMetadata, будем слушать действия запроса getNotifications и хранить объекты "только метаданных" в слайсе вместо полных уведомлений.
В рамках этого мы переименуем notificationsAdapter в metadataAdapter и заменим все упоминания переменных notification на metadata для ясности. Изменений много, но по сути это просто переименование.
Также экспортируем селектор selectEntities адаптера сущностей как selectMetadataEntities. Нам потребуется искать эти объекты метаданных по ID в интерфейсе, и наличие таблицы поиска в компоненте упростит задачу.
// omit imports and thunks
// Replaces `ClientNotification`, since we just need these fields
export interface NotificationMetadata {
// Add an `id` field, since this is now a standalone object
id: string
read: boolean
isNew: boolean
}
export const fetchNotifications = createAppAsyncThunk(
'notifications/fetchNotifications',
async (_unused, thunkApi) => {
// Deleted timestamp lookups - we're about to remove this thunk anyway
const response = await client.get<ServerNotification[]>(
`/fakeApi/notifications`
)
return response.data
}
)
// Renamed from `notificationsAdapter`, and we don't need sorting
const metadataAdapter = createEntityAdapter<NotificationMetadata>()
const initialState = metadataAdapter.getInitialState()
const notificationsSlice = createSlice({
name: 'notifications',
initialState,
reducers: {
allNotificationsRead(state) {
// Rename to `metadata`
Object.values(state.entities).forEach(metadata => {
metadata.read = true
})
}
},
extraReducers(builder) {
// Listen for the endpoint `matchFulfilled` action with `addMatcher`
builder.addMatcher(
apiSliceWithNotifications.endpoints.getNotifications.matchFulfilled,
(state, action) => {
// Add client-side metadata for tracking new notifications
const notificationsMetadata: NotificationMetadata[] =
action.payload.map(notification => ({
// Give the metadata object the same ID as the notification
id: notification.id,
read: false,
isNew: true
}))
// Rename to `metadata`
Object.values(state.entities).forEach(metadata => {
// Any notifications we've read are no longer new
metadata.isNew = !metadata.read
})
metadataAdapter.upsertMany(state, notificationsMetadata)
}
)
}
})
export const { allNotificationsRead } = notificationsSlice.actions
export default notificationsSlice.reducer
// Rename the selector
export const {
selectAll: selectAllNotificationsMetadata,
selectEntities: selectMetadataEntities
} = metadataAdapter.getSelectors(
(state: RootState) => state.notifications
)
export const selectUnreadNotificationsCount = (state: RootState) => {
const allMetadata = selectAllNotificationsMetadata(state)
const unreadNotifications = allMetadata.filter(metadata => !metadata.read)
return unreadNotifications.length
}
Теперь мы можем прочитать эту таблицу поиска в <NotificationsList>, найти правильный объект метаданных для каждого отображаемого уведомления и снова включить проверку isNew для правильного стилистического оформления:
import { allNotificationsRead, useGetNotificationsQuery, selectMetadataEntities } from './notificationsSlice'
export const NotificationsList = () => {
const dispatch = useAppDispatch()
const { data: notifications = [] } = useGetNotificationsQuery()
const notificationsMetadata = useAppSelector(selectMetadataEntities)
useLayoutEffect(() => {
dispatch(allNotificationsRead())
})
const renderedNotifications = notifications.map((notification) => {
// Get the metadata object matching this notification
const metadata = notificationsMetadata[notification.id]
const notificationClassname = classnames('notification', {
// re-enable the `isNew` check for styling
new: metadata.isNew,
})
// omit rendering
}
}
Теперь во вкладке "Уведомления" новые уведомления стилизованы правильно... но мы по-прежнему не получаем дополнительные уведомления, и существующие не помечаются как прочитанные.
Отправка уведомлений через Websocket
Осталось выполнить несколько шагов для полного перехода на получение уведомлений через серверную push-рассылку.
Следующий шаг — изменить поведение кнопки "Обновить уведомления": вместо диспетчеризации асинхронного thunk'а для HTTP-запроса мы заставим моковый бэкенд отправлять уведомления через websocket.
Наш файл src/api/server.ts уже содержит сконфигурированный моковый Websocket-сервер, аналогичный моковому HTTP-серверу. Поскольку у нас нет реального бэкенда (или других пользователей!), нам всё ещё нужно вручную указывать моковому серверу, когда отправлять новые уведомления. Для этого server.ts экспортирует функцию forceGenerateNotifications, которая заставит бэкенд отправить несколько уведомлений через websocket.
Мы заменим асинхронный thunk fetchNotifications на thunk fetchNotificationsWebsocket. fetchNotificationsWebsocket выполняет ту же работу, что и существующий асинхронный thunk fetchNotifications. Однако в данном случае мы не делаем реальный HTTP-запрос, поэтому нет вызова await и нет возвращаемого payload'а. Мы просто вызываем функцию, которую экспортировал server.ts специально для эмуляции серверных push-уведомлений.
Поэтому fetchNotificationsWebsocket не требует createAsyncThunk. Это обычный thunk, так что мы можем использовать тип AppThunk для корректной типизации (dispatch, getState).
Для реализации проверки "последней временной метки" нам нужны селекторы, читающие кэшированную запись уведомлений. Используем тот же подход, что и в users slice.
import {
createEntityAdapter,
createSlice,
createSelector
} from '@reduxjs/toolkit'
import { forceGenerateNotifications } from '@/api/server'
import type { AppThunk, RootState } from '@/app/store'
import { apiSlice } from '@/features/api/apiSlice'
// omit types and API slice setup
export const { useGetNotificationsQuery } = apiSliceWithNotifications
export const fetchNotificationsWebsocket =
(): AppThunk => (dispatch, getState) => {
const allNotifications = selectNotificationsData(getState())
const [latestNotification] = allNotifications
const latestTimestamp = latestNotification?.date ?? ''
// Hardcode a call to the mock server to simulate a server push scenario over websockets
forceGenerateNotifications(latestTimestamp)
}
const emptyNotifications: ServerNotification[] = []
export const selectNotificationsResult =
apiSliceWithNotifications.endpoints.getNotifications.select()
const selectNotificationsData = createSelector(
selectNotificationsResult,
notificationsResult => notificationsResult.data ?? emptyNotifications
)
// omit slice and selectors
Теперь мы можем изменить <Navbar> для отправки fetchNotificationsWebsocket вместо текущего действия:
import {
fetchNotificationsWebsocket,
selectUnreadNotificationsCount,
} from '@/features/notifications/notificationsSlice'
import { selectCurrentUser } from '@/features/users/usersSlice'
import { UserIcon } from './UserIcon'
export const Navbar = () => {
// omit hooks
if (isLoggedIn) {
const onLogoutClicked = () => {
dispatch(logout())
}
const fetchNewNotifications = () => {
dispatch(fetchNotificationsWebsocket())
}
Почти готово! Мы получаем начальные уведомления через RTK Query, отслеживаем статус прочтения на клиенте и настроили инфраструктуру для push-уведомлений через websocket. Но если сейчас нажать "Обновить уведомления", возникнет ошибка — обработка websocket ещё не реализована!
Итак, реализуем логику обработки потоковых обновлений.
Реализация потоковых обновлений
Концептуально нам нужно: проверять уведомления сразу после входа пользователя и постоянно слушать новые обновления. При выходе — прекращать прослушивание.
Компонент <Navbar> рендерится после входа и остаётся видимым всё время — идеальное место для поддержания подписки на кэш. Для этого вызовем хук useGetNotificationsQuery() в этом компоненте.
// omit other imports
import {
fetchNotificationsWebsocket,
selectUnreadNotificationsCount,
useGetNotificationsQuery
} from '@/features/notifications/notificationsSlice'
export const Navbar = () => {
const dispatch = useAppDispatch()
const user = useAppSelector(selectCurrentUser)
// Trigger initial fetch of notifications and keep the websocket open to receive updates
useGetNotificationsQuery()
// omit rest of the component
}
Последний шаг — добавить обработчик жизненного цикла onCacheEntryAdded в эндпоинт getNotifications и реализовать логику работы с websocket.
Создадим новый websocket, подпишемся на входящие сообщения, прочитаем из них уведомления и обновим кэш RTKQ новыми данными. Концептуально это похоже на оптимистичные обновления в onQueryStarted.
Есть ещё один нюанс: при получении уведомлений через websocket не диспетчеризуется явный action "запрос выполнен", но нам всё равно нужно создавать метаданные для новых уведомлений.
Решим это созданием специального Redux-экшена, сигнализирующего о "получении новых уведомлений". Будем диспетчеризовать его из websocket-обработчика, а в notificationsSlice добавим обработку как эндпоинтных экшенов, так и этого нового экшена через утилиту isAnyOf, применяя одинаковую логику метаданных в обоих случаях.
import {
createEntityAdapter,
createSlice,
createSelector,
createAction,
isAnyOf
} from '@reduxjs/toolkit'
// omit imports and other code
const notificationsReceived = createAction<ServerNotification[]>('notifications/notificationsReceived')
export const apiSliceWithNotifications = apiSlice.injectEndpoints({
endpoints: builder => ({
getNotifications: builder.query<ServerNotification[], void>({
query: () => '/notifications',
async onCacheEntryAdded(arg, lifecycleApi) {
// create a websocket connection when the cache subscription starts
const ws = new WebSocket('ws://localhost')
try {
// wait for the initial query to resolve before proceeding
await lifecycleApi.cacheDataLoaded
// when data is received from the socket connection to the server,
// update our query result with the received message
const listener = (event: MessageEvent<string>) => {
const message: {
type: 'notifications'
payload: ServerNotification[]
} = JSON.parse(event.data)
switch (message.type) {
case 'notifications': {
lifecycleApi.updateCachedData(draft => {
// Insert all received notifications from the websocket
// into the existing RTKQ cache array
draft.push(...message.payload)
draft.sort((a, b) => b.date.localeCompare(a.date))
})
// Dispatch an additional action so we can track "read" state
lifecycleApi.dispatch(notificationsReceived(message.payload))
break
}
default:
break
}
}
ws.addEventListener('message', listener)
} catch {
// no-op in case `cacheEntryRemoved` resolves before `cacheDataLoaded`,
// in which case `cacheDataLoaded` will throw
}
// cacheEntryRemoved will resolve when the cache subscription is no longer active
await lifecycleApi.cacheEntryRemoved
// perform cleanup steps once the `cacheEntryRemoved` promise resolves
ws.close()
}
})
})
})
export const { useGetNotificationsQuery } = apiSliceWithNotifications
const matchNotificationsReceived = isAnyOf(
notificationsReceived,
apiSliceWithNotifications.endpoints.getNotifications.matchFulfilled,
)
// omit other code
const notificationsSlice = createSlice({
name: 'notifications',
initialState,
reducers: { /* omit reducers */ },
extraReducers(builder) {
builder.addMatcher(matchNotificationsReceived, (state, action) => {
// omit logic
}
},
})
При добавлении записи в кэш создаём новый экземпляр WebSocket, подключающийся к моковому серверу.
Ожидаем разрешения промиса lifecycleApi.cacheDataLoaded — это сигнализирует о завершении запроса и доступности данных.
Нам нужно подписаться на входящие сообщения из вебсокета. Наш колбэк будет получать событие MessageEvent, и мы знаем, что event.data будет строкой с JSON-сериализованными данными уведомлений от бэкенда.
При получении сообщения мы парсим его содержимое и проверяем, соответствует ли распаршенный объект ожидаемому типу сообщения. Если да, вызываем lifecycleApi.updateCachedData(), добавляем новые уведомления в существующую кэш-запись и пересортировываем, чтобы сохранить правильный порядок.
Наконец, мы можем ожидать разрешения промиса lifecycleApi.cacheEntryRemoved, чтобы узнать, когда нужно закрыть вебсокет и выполнить очистку.
Важно: создание вебсокета непосредственно в методе жизненного цикла не является обязательным. В зависимости от структуры приложения вы могли создать его ранее при настройке, и он может находиться в другом модуле или собственном Redux-мидлваре. Ключевой момент здесь — использование onCacheEntryAdded для отслеживания момента начала прослушивания данных, вставки результатов в кэш и очистки при удалении кэш-записи.
Готово! Теперь при клике "Refresh Notifications" мы должны увидеть увеличение счётчика непрочитанных уведомлений, а переключение на вкладку "Notifications" будет корректно подсвечивать прочитанные и непрочитанные уведомления.
Финализация
На завершающем этапе выполним дополнительную очистку. Вызов createSlice в postsSlice.ts больше не используется, поэтому можем удалить объект слайса и связанные с ним селекторы + типы, затем убрать postsReducer из Redux-стора. Функцию addPostsListeners и типы оставим — это подходящее место для данного кода.
Итоги изученного
На этом завершена миграция приложения на RTK Query! Весь фетчинг данных переведён на RTKQ, а пользовательский опыт улучшен за счёт оптимистичных обновлений и стриминговых апдейтов.
Как мы убедились, RTK Query предоставляет мощные инструменты для управления кэшированными данными. Хотя не все опции могут потребоваться сразу, они обеспечивают гибкость и ключевые возможности для реализации специфического поведения приложений.
В заключение оценим работу приложения в действии:
- Специфичные кэш-теги обеспечивают детализированную инвалидацию кэша
- Теги могут быть
'Post'или{type: 'Post', id} - Эндпоинты могут предоставлять или инвалидировать теги на основе ключей кэша
- Теги могут быть
- API RTK Query независимы от UI и работают вне React
- Объекты эндпоинтов включают функции для инициации запросов, генерации селекторов и обработки экшенов
- Ответы можно трансформировать различными способами
- Эндпоинты определяют
transformResponseдля модификации данных перед кэшированием - Хуки поддерживают опцию
selectFromResultдля извлечения/трансформации данных - Компоненты могут читать полные значения и трансформировать через
useMemo
- Эндпоинты определяют
- Продвинутые опции RTK Query для манипуляции кэшем улучшают UX
- Лайфсайкл
onQueryStartedобеспечивает оптимистичные обновления через апдейт кэша перед ответом сервера onCacheEntryAddedподдерживает стриминговые обновления через постоянные соединения- Эндпоинты RTKQ имеют матчер
matchFulfilledдля отслеживания экшенов и запуска дополнительной логики
- Лайфсайкл
Что дальше?
Поздравляем, вы завершили туториал по Redux Essentials! Теперь вы должны понимать принципы работы Redux Toolkit и React-Redux, уметь писать и организовывать Redux-логику, работать с потоком данных Redux в React, использовать API вроде configureStore и createSlice. Вы также знаете, как RTK Query упрощает фетчинг и использование кэшированных данных.
Подробнее об использовании RTK Query см. в документации по использованию RTK Query и справочнике API.
Концепции, рассмотренные в этом руководстве, должны дать достаточную основу для создания собственных приложений с использованием React и Redux. Сейчас идеальное время попрактиковаться в проекте, чтобы закрепить знания и увидеть их применение. Если вы не знаете, какой проект создать, посмотрите список идей для приложений для вдохновения.
Это руководство по Redux Essentials фокусируется на "как правильно использовать Redux", а не на "как он работает" или "почему он устроен именно так". Особенно важно, что Redux Toolkit представляет собой набор высокоуровневых абстракций и утилит, и полезно понимать, что именно делают эти абстракции за вас. Прохождение руководства "Redux Fundamentals" поможет понять, как писать Redux-код "вручную" и почему мы рекомендуем Redux Toolkit как стандартный способ работы.
Раздел Использование Redux содержит информацию по важным темам, например структурированию редьюсеров, а руководство по стилю описывает рекомендуемые паттерны и лучшие практики.
Чтобы узнать больше о том, почему создан Redux, какие проблемы он решает и как его следует использовать, прочтите статьи сопровождающего Redux Марка Эриксона: The Tao of Redux, Part 1: Implementation and Intent и The Tao of Redux, Part 2: Practice and Philosophy.
Если вам нужна помощь по Redux, присоединяйтесь к каналу #redux в Discord-сервере Reactiflux.
Спасибо за прочтение этого руководства, желаем успехов в создании приложений с Redux!