Reduxエッセンシャルズ Part 8: RTK Query高度なパターン
このページは PageTurner AI で翻訳されました(ベータ版)。プロジェクト公式の承認はありません。 エラーを見つけましたか? 問題を報告 →
- ID付きタグを使ったキャッシュ無効化と再取得の管理方法
- React外でのRTK Queryキャッシュ操作
- レスポンスデータ操作テクニック
- 楽観的更新とストリーミング更新の実装
- Part 7の完了(RTK Queryの基本設定と使用方法の理解)
はじめに
Part 7: RTK Query基礎では、アプリケーションでのデータ取得とキャッシュ処理のためにRTK Query APIを設定・使用する方法を学びました。Reduxストアに「APIスライス」を追加し、投稿データを取得する「クエリ」エンドポイントと、新規投稿を追加する「ミューテーション」エンドポイントを定義しました。
このセクションでは、他のデータタイプでもRTK Queryを使用するようにサンプルアプリを移行しつつ、高度な機能を活用してコードベースを簡素化しユーザーエクスペリエンスを向上させる方法を紹介します。
このセクションの変更の一部は必須ではありません。RTK Queryの機能をデモンストレーションし、必要に応じて活用できることを示すために含まれています。
投稿の編集
新規投稿をサーバーに保存するミューテーションエンドポイントは<AddPostForm>で既に追加済みです。次に、既存の投稿を編集できるように<EditPostForm>を更新する必要があります。
投稿編集フォームの更新
新規投稿の追加と同様に、最初のステップはAPIスライスに新しいミューテーションエンドポイントを定義することです。これは投稿追加のミューテーションと似ていますが、エンドポイントはURLに投稿IDを含め、一部のフィールドを更新することを示すHTTP PATCHリクエストを使用する必要があります。
export const apiSlice = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
tagTypes: ['Post'],
endpoints: builder => ({
getPosts: builder.query<Post[], void>({
query: () => '/posts',
providesTags: ['Post']
}),
getPost: builder.query<Post, string>({
query: postId => `/posts/${postId}`
}),
addNewPost: builder.mutation<Post, NewPost>({
query: initialPost => ({
url: '/posts',
method: 'POST',
body: initialPost
}),
invalidatesTags: ['Post']
}),
editPost: builder.mutation<Post, PostUpdate>({
query: post => ({
url: `posts/${post.id}`,
method: 'PATCH',
body: post
})
})
})
})
export const {
useGetPostsQuery,
useGetPostQuery,
useAddNewPostMutation,
useEditPostMutation
} = apiSlice
エンドポイント追加後、<EditPostForm>を更新できます。フォームはストアから元のPostエントリを読み取り、フィールド編集用のコンポーネント状態を初期化し、更新内容をサーバーに送信する必要があります。現在はselectPostByIdでPostエントリを読み取り、リクエストにpostUpdatedスンクを手動でディスパッチしています。
<SinglePostPage>で使用したのと同じuseGetPostQueryフックでストア内のキャッシュからPostエントリを読み取れます。更新内容の保存には新しいuseEditPostMutationフックを使用します。必要に応じて、更新処理中にスピナーを表示したりフォーム入力を無効化することも可能です。
import React from 'react'
import { useNavigate, useParams } from 'react-router-dom'
import { Spinner } from '@/components/Spinner'
import { useGetPostQuery, useEditPostMutation } from '@/features/api/apiSlice'
// omit form types
export const EditPostForm = () => {
const { postId } = useParams()
const navigate = useNavigate()
const { data: post } = useGetPostQuery(postId!)
const [updatePost, { isLoading }] = useEditPostMutation()
if (!post) {
return (
<section>
<h2>Post not found!</h2>
</section>
)
}
const onSavePostClicked = async (
e: React.FormEvent<EditPostFormElements>
) => {
// Prevent server submission
e.preventDefault()
const { elements } = e.currentTarget
const title = elements.postTitle.value
const content = elements.postContent.value
if (title && content) {
await updatePost({ id: post.id, title, content })
navigate(`/posts/${postId}`)
}
}
// omit rendering
}
キャッシュデータのサブスクリプション寿命
実際に試して動作を確認しましょう。ブラウザのDevToolsを開き、Networkタブに移動します。ページを更新後、ネットワークタブをクリアしてログインしてください。初期データ取得のため/postsへのGETリクエストが表示されます。「投稿を表示」ボタンをクリックすると、単一の投稿エントリを返す/posts/:postIdへの2番目のリクエストが表示されます。
次に投稿詳細ページ内の「投稿を編集」をクリックしてください。UIが<EditPostForm>に切り替わりますが、今回は個別投稿のネットワークリクエストが発生しません。なぜでしょうか?

RTK Queryは複数のコンポーネントが同じデータを購読することを許可し、各ユニークなデータセットが一度だけフェッチされることを保証します。 内部的にRTK Queryは、各エンドポイントとキャッシュキーの組み合わせに対するアクティブな「サブスクリプション」の参照カウンターを保持しています。コンポーネントAがuseGetPostQuery(42)を呼び出すと、そのデータがフェッチされます。その後コンポーネントBがマウントされ同じくuseGetPostQuery(42)を呼び出す場合、同じデータを要求しています。既存のキャッシュエントリが存在するため、リクエストは不要です。両方のフック使用箇所は、フェッチしたdataやローディング状態フラグを含め、全く同じ結果を返します。
アクティブなサブスクリプション数が0になると、RTK Queryは内部タイマーを開始します。タイマーが切れる前に新しいデータサブスクリプションが追加されない場合、RTK Queryはそのデータをキャッシュから自動的に削除します。これはアプリがそのデータを不要になったためです。ただし、タイマーが切れる前に新しいサブスクリプションが追加された場合、タイマーはキャンセルされ、既存のキャッシュデータが再フェッチなしで使用されます。
このケースでは、<SinglePostPage>がマウントされIDで個別のPostを要求しました。「Edit Post」をクリックすると、<SinglePostPage>コンポーネントはルーターによってアンマウントされ、アクティブなサブスクリプションが削除されます。RTK Queryは直ちに「この投稿データを削除」するタイマーを開始します。しかし、<EditPostPage>コンポーネントがすぐにマウントされ、同じキャッシュキーで同じPostデータを購読します。そのためRTK Queryはタイマーをキャンセルし、サーバーから再フェッチする代わりに同じキャッシュデータを使い続けます。
デフォルトでは未使用データは60秒後にキャッシュから削除されますが、これはルートAPIスライス定義で設定するか、個別のエンドポイント定義でkeepUnusedDataForフラグ(キャッシュ生存時間を秒単位で指定)を使用して上書きできます。
特定アイテムの無効化
<EditPostForm>コンポーネントは編集した投稿をサーバーに保存できるようになりましたが、問題があります。「Save Post」をクリックすると<SinglePostPage>に戻りますが、編集内容が反映されていない古いデータが表示されたままです。<SinglePostPage>は以前フェッチしたキャッシュされたPostエントリをまだ使用しています。同様にメインページに戻って<PostsList>を見ると、こちらも古いデータを表示しています。個別のPostエントリと投稿リスト全体の両方を強制的に再フェッチする方法が必要です。
以前、キャッシュデータの一部を無効化するために「タグ」を使用する方法を見ました。getPostsクエリエンドポイントが'Post'タグを提供(provide)し、addNewPostミューテーションエンドポイントが同じ'Post'タグを無効化(invalidate)するよう宣言しました。これにより、新しい投稿を追加するたびにgetQueryエンドポイントから投稿リスト全体を再フェッチさせています。
getPostクエリとeditPostミューテーションの両方に'Post'タグを追加することも可能ですが、他の個別投稿もすべて再フェッチされてしまいます。幸いにもRTK Queryは特定タグを定義でき、データ無効化をより選択的に行えます。これらの特定タグは{type: 'Post', id: 123}の形式になります。
getPostsクエリは文字列の配列であるprovidesTagsフィールドを定義しています。providesTagsフィールドはresultとargを受け取るコールバック関数も受け入れ、配列を返します。これによりフェッチされるデータのIDに基づいてタグエントリを作成できます。同様にinvalidatesTagsもコールバック形式にできます。
適切な動作を得るには、各エンドポイントに正しいタグを設定する必要があります:
-
getPosts: リスト全体に対して一般的な'Post'タグを提供すると同時に、受信した各投稿オブジェクトに対して特定の{type: 'Post', id}タグを提供 -
getPost: 個別の投稿オブジェクトに対して特定の{type: 'Post', id}オブジェクトを提供 -
addNewPost: 一般的な'Post'タグを無効化し、リスト全体を再取得 -
editPost: 特定の{type: 'Post', id}タグを無効化。これによりgetPostからの個別投稿とgetPostsからの投稿リスト全体の両方が再取得されます。なぜなら両エンドポイントがこの{type, id}値にマッチするタグを提供しているからです。
export const apiSlice = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
tagTypes: ['Post'],
endpoints: builder => ({
getPosts: builder.query<Post[], void>({
query: () => '/posts',
providesTags: (result = [], error, arg) => [
'Post',
...result.map(({ id }) => ({ type: 'Post', id }) as const)
]
}),
getPost: builder.query<Post, string>({
query: postId => `/posts/${postId}`,
providesTags: (result, error, arg) => [{ type: 'Post', id: arg }]
}),
addNewPost: builder.mutation<Post, NewPost>({
query: initialPost => ({
url: '/posts',
method: 'POST',
body: initialPost
}),
invalidatesTags: ['Post']
}),
editPost: builder.mutation<Post, PostUpdate>({
query: post => ({
url: `posts/${post.id}`,
method: 'PATCH',
body: post
}),
invalidatesTags: (result, error, arg) => [{ type: 'Post', id: arg.id }]
})
})
})
これらのコールバックの result 引数は、レスポンスにデータがない場合やエラー時に undefined になる可能性があるため、安全に処理する必要があります。getPosts ではデフォルトの配列値を使用してマッピングできます。getPost では引数の ID に基づいて単一アイテムの配列を返すように既に実装されています。editPost ではトリガー関数に渡された部分投稿オブジェクトから投稿 ID を取得できます。
これらの変更を加えたら、ブラウザの DevTools で Network タブを開きながら投稿編集を再試行しましょう。
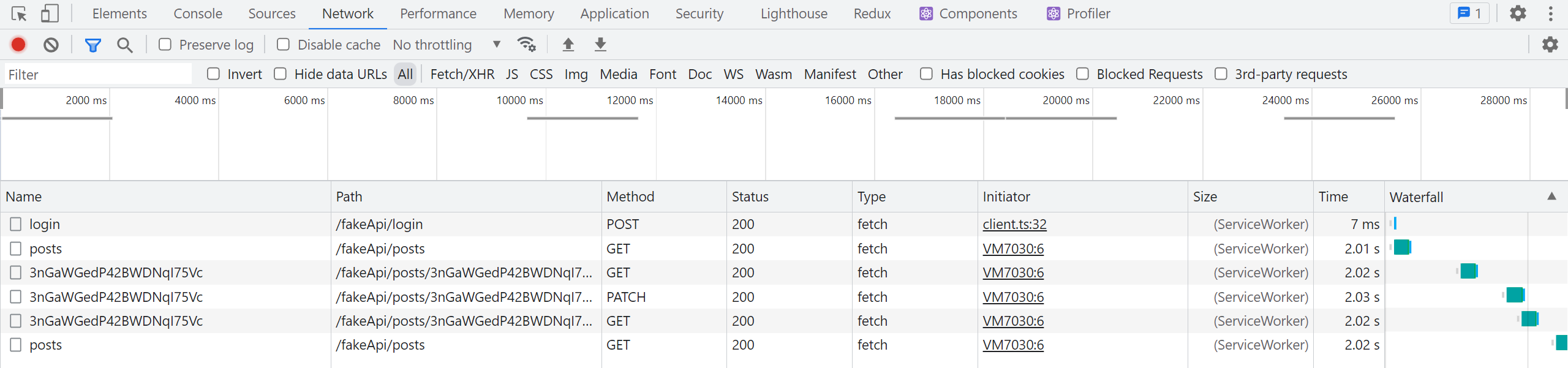
編集した投稿を保存すると、連続して2つのリクエストが発生します:
-
editPostmutation によるPATCH /posts/:postId -
getPostquery の再取得によるGET /posts/:postId
メインの "Posts" タブに戻るとさらに以下が発生します:
getPostsquery の再取得によるGET /posts
エンドポイント間の関係をタグで定義したため、編集時に特定のIDタグが無効化されると、RTK Query は個別投稿と投稿リストの両方を再取得する必要があることを自動認識します - 追加変更は不要です!一方、投稿編集中に getPosts データのキャッシュタイマーが期限切れになったため、キャッシュから削除されました。再度 <PostsList> コンポーネントを開くと、RTK Query はキャッシュにデータがないことを検知し再取得します。
注意点が1つあります。getPosts でプレーンな 'Post' タグを指定し addNewPost で無効化すると、実際には全ての個別投稿も再取得されてしまいます。getPosts エンドポイントの投稿リストのみを再取得したい場合は、{type: 'Post', id: 'LIST'} のような任意のIDを持つ追加タグを設定し、代わりにそのタグを無効化できます。RTK Query ドキュメントには特定の一般/個別タグ組み合わせが無効化された際の動作を説明する表があります。
RTK Query にはデータ再取得のタイミングと方法を制御する多くのオプションがあります:
-
「条件付きフェッチ」
-
「遅延クエリ」
-
「プリフェッチ」 クエリ定義も多様な方法でカスタマイズ可能です。詳細は RTK Query 使用ガイドを参照してください:
トースト表示の更新
投稿追加をサンクから RTK Query mutation に切り替えた際、addNewPost.fulfilled アクションがディスパッチされなくなったため、「新規投稿が追加されました」というトーストメッセージの動作が意図せず無効化されました。
幸いなことに、これは簡単に修正できます。RTK Queryは内部的にcreateAsyncThunkを使用しており、リクエストが行われる際にReduxアクションをディスパッチすることが既に確認されています。トーストリスナーを更新して、RTKQの内部アクションがディスパッチされるのを監視し、その際にトーストメッセージを表示するようにできます。
createApiは各エンドポイントに対して内部的にthunkを自動生成します。またRTKの「matcher」関数も自動生成します。これはアクションオブジェクトを受け取り、条件に一致する場合にtrueを返す関数です。これらのmatcherは、startAppListening内などでアクションが特定の条件に一致するかどうかを確認する必要がある場所で使用できます。またTypeScriptの型ガードとしても機能し、actionオブジェクトのTS型を絞り込むことで安全にフィールドにアクセスできます。
現在、トーストリスナーはactionCreator: addNewPost.fulfilledで特定のアクションタイプを監視しています。これをmatcher: apiSlice.endpoints.addNewPost.matchFulfilledを使用して投稿が追加されたことを監視するように更新します:
import { createEntityAdapter, createSelector, createSlice, EntityState, PayloadAction } from '@reduxjs/toolkit'
import { client } from '@/api/client'
import type { RootState } from '@/app/store'
import { AppStartListening } from '@/app/listenerMiddleware'
import { createAppAsyncThunk } from '@/app/withTypes'
import { apiSlice } from '@/features/api/apiSlice'
import { logout } from '@/features/auth/authSlice'
// omit types, posts slice, and selectors
export const addPostsListeners = (startAppListening: AppStartListening) => {
startAppListening({
matcher: apiSlice.endpoints.addNewPost.matchFulfilled,
effect: async (action, listenerApi) => {
これで投稿を追加した際にトーストが正しく表示されるようになります。
ユーザーデータの管理
投稿データ管理のRTK Queryへの移行が完了しました。次にユーザーリストの移行に取り掛かります。
データの取得と読み取りにRTK Queryフックを使用する方法は既に見てきたので、このセクションでは別のアプローチを試みます。Redux Toolkitの他の部分と同様に、RTK QueryのコアロジックはUIに依存せず、Reactだけでなく任意のUI層で使用できます。
通常はcreateApiが生成するReactフックを使用すべきです(多くの処理を代行してくれます)。しかし説明のため、ここではRTK QueryのコアAPIのみを使用してユーザーデータを操作し、その使用方法を示します。
ユーザーの手動取得
現在usersSlice.tsでfetchUsers非同期thunkを定義し、main.tsxでこのthunkを手動でディスパッチして、可能な限り早くユーザーリストを利用可能にしています。この同じプロセスをRTK Queryで実行できます。
まずapiSlice.tsに既存のエンドポイントと同様にgetUsersクエリエンドポイントを定義します。一貫性のためにuseGetUsersQueryフックもエクスポートしますが、当面は使用しません。
import { createApi, fetchBaseQuery } from '@reduxjs/toolkit/query/react'
import type { Post, NewPost, PostUpdate } from '@/features/posts/postsSlice'
import type { User } from '@/features/users/usersSlice'
export type { Post }
export const apiSlice = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
tagTypes: ['Post'],
endpoints: builder => ({
// omit other endpoints
getUsers: builder.query<User[], void>({
query: () => '/users'
})
})
})
export const {
useGetPostsQuery,
useGetPostQuery,
useGetUsersQuery,
useAddNewPostMutation,
useEditPostMutation
} = apiSlice
APIスライスオブジェクトを検査すると、endpointsフィールドが含まれており、定義した各エンドポイントに対応するオブジェクトが格納されています。

各エンドポイントオブジェクトには以下が含まれます:
-
ルートAPIスライスオブジェクトからエクスポートしたものと同じプライマリクエリ/ミューテーションフック(
useQueryまたはuseMutationという名前) -
クエリエンドポイントの場合、「レイジークエリ」や部分的なサブスクリプションなどのシナリオ用の追加クエリフック
-
このエンドポイントのリクエストによってディスパッチされる
pending/fulfilled/rejectedアクションをチェックする「matcher」ユーティリティのセット -
このエンドポイントのリクエストをトリガーする
initiatethunk -
このエンドポイントのキャッシュされた結果データとステータスエントリを取得できるメモ化セレクターを作成する
select関数
React外でユーザーリストを取得したい場合、indexファイルでgetUsers.initiate() thunkをディスパッチできます:
// omit other imports
import { apiSlice } from './features/api/apiSlice'
async function main() {
// Start our mock API server
await worker.start({ onUnhandledRequest: 'bypass' })
store.dispatch(apiSlice.endpoints.getUsers.initiate())
const root = createRoot(document.getElementById('root')!)
root.render(
<React.StrictMode>
<Provider store={store}>
<App />
</Provider>
</React.StrictMode>
)
}
main()
このディスパッチはクエリフック内で自動的に行われますが、必要に応じてinitiate thunkを手動で起動することも可能です。
initiate() に引数を渡さなかった点に注意してください。これは、getUsers エンドポイントが特定のクエリ引数を必要としないためです。概念的には「このキャッシュエントリのクエリ引数は undefined である」と言うのと同じです。引数が必要な場合は、サンクに渡します(例: dispatch(apiSlice.endpoints.getPokemon.initiate('pikachu')))。
このケースでは、アプリのセットアップ関数内でデータのプリフェッチを開始するために、手動でサンクをディスパッチしています。実際には、コンポーネントがレンダリングされる前にリクエストを開始するために、React Routerの「データローダー」でプリフェッチを行うことをお勧めします(実装アイデアについてはRTKリポジトリのReact Routerローダーに関するディスカッションを参照)。
RTKQリクエストサンクを手動でディスパッチするとサブスクリプションエントリが作成されますが、その後はデータのサブスクリプション解除が必要です。解除しない場合、データはキャッシュに永続的に残ります。今回のケースではユーザーデータが常に必要なので、サブスクリプション解除をスキップできます。
ユーザーデータの選択
現在、createEntityAdapterユーザーアダプターによって生成されたselectAllUsersやselectUserByIdといったセレクターがあり、これらはstate.usersからデータを読み取っています。ページをリロードすると、state.usersスライスにデータがないためユーザー関連の表示がすべて壊れます。RTK Queryキャッシュ用にデータを取得しているので、これらのセレクターをキャッシュから読み取る同等のものに置き換える必要があります。
APIスライスエンドポイントのendpoint.select()関数は、呼び出すたびに新しいメモ化されたセレクター関数を生成します。select()はキャッシュキーを引数として受け取り、これはクエリフックやinitiate()サンクに渡すキャッシュキーと_同一_である必要があります。生成されたセレクターはこのキャッシュキーを使用し、ストアのキャッシュ状態から返すべきキャッシュ結果を正確に特定します。
今回のケースでは、getUsersエンドポイントはパラメータを必要としません(常に全ユーザーリストを取得します)。したがって、引数なしでキャッシュセレクターを作成できます(これはキャッシュキーとしてundefinedを渡すのと同じです)。
usersSlice.tsを更新し、実際のusersSlice呼び出しではなくRTKQクエリキャッシュに基づいてセレクターを定義できます:
import {
createEntityAdapter,
createSelector,
createSlice
} from '@reduxjs/toolkit'
import { client } from '@/api/client'
import type { RootState } from '@/app/store'
import { createAppAsyncThunk } from '@/app/withTypes'
import { apiSlice } from '@/features/api/apiSlice'
import { selectCurrentUsername } from '@/features/auth/authSlice'
export interface User {
id: string
name: string
}
// omit `fetchUsers` and `usersSlice`
const emptyUsers: User[] = []
// Calling `someEndpoint.select(someArg)` generates a new selector that will return
// the query result object for a query with those parameters.
// To generate a selector for a specific query argument, call `select(theQueryArg)`.
// In this case, the users query has no params, so we don't pass anything to select()
export const selectUsersResult = apiSlice.endpoints.getUsers.select()
export const selectAllUsers = createSelector(
selectUsersResult,
usersResult => usersResult?.data ?? emptyUsers
)
export const selectUserById = createSelector(
selectAllUsers,
(state: RootState, userId: string) => userId,
(users, userId) => users.find(user => user.id === userId)
)
export const selectCurrentUser = (state: RootState) => {
const currentUsername = selectCurrentUsername(state)
if (currentUsername) {
return selectUserById(state, currentUsername)
}
}
/* Temporarily ignore adapter selectors - we'll come back to this later
export const { selectAll: selectAllUsers, selectById: selectUserById } = usersAdapter.getSelectors(
(state: RootState) => state.users,
)
*/
まず、適切なキャッシュエントリを取得する方法を知っているselectUsersResultセレクターインスタンスを作成します。
このselectUsersResultセレクターが用意できたら、既存のselectAllUsersセレクターをキャッシュ結果からユーザー配列を返すものに置き換えます。有効な結果がない可能性があるため、emptyUsers配列にフォールバックします。同様にselectUserByIdも、この配列から適切なユーザーを検索するものに置き換えます。
一時的にusersAdapterからこれらのセレクターをコメントアウトします(後でこれらの使用に戻す変更を加えます)。
コンポーネントは既にselectAllUsers、selectUserById、selectCurrentUserをインポートしているので、この変更は即座に反映されます!ページをリロードし、投稿リストと個別投稿ビューを操作してみてください。各投稿と<AddPostForm>のドロップダウンに正しいユーザー名が表示されるはずです。
これはセレクターを使用することでコードの保守性がどのように向上するかを示す好例です! コンポーネントは既にこれらのセレクターを呼び出しているため、データが既存のusersSliceステートから来ているのかRTK Queryキャッシュエントリから来ているのかは気にしません。セレクターが期待されるデータを返す限り、セレクターの実装を変更してもUIコンポーネントを全く更新する必要がありませんでした。
usersSliceの状態が全く使用されなくなったため、このファイルからconst usersSlice = createSlice()呼び出しとfetchUsersサンクを削除し、ストア設定からusers: usersReducerを削除できます。postsSliceを参照するコードがまだいくつか残っているため、完全には削除できませんが、すぐに対処します。
エンドポイントの分割と注入
RTK Queryでは通常、アプリケーションごとに単一の「APIスライス」を定義します。これまで全てのエンドポイントをapiSlice.tsに直接定義してきました。しかし大規模アプリケーションでは、機能を別々のバンドルに「コードスプリット」し、その機能が初めて使用される際にオンデマンドで「レイジーロード」するのが一般的です。エンドポイント定義をコードスプリットしたい場合、あるいはAPIスライスファイルが肥大化しないように別ファイルに移動したい場合はどうすればよいでしょうか?
RTK QueryはapiSlice.injectEndpoints()によるエンドポイント定義の分割をサポートしています。これにより、単一のAPIスライスインスタンス(単一のミドルウェアとキャッシュリデューサ)を維持しつつ、一部のエンドポイント定義を他のファイルに移動できます。これによりコード分割シナリオが可能になるほか、必要に応じて機能フォルダに関連するエンドポイントを同居させることもできます。
このプロセスを説明するため、getUsersエンドポイントをapiSlice.tsで定義する代わりに、usersSlice.tsに注入するよう変更しましょう。
getUsersエンドポイントにアクセスするため、apiSliceをusersSlice.tsにすでにインポートしているので、代わりにapiSlice.injectEndpoints()をここで呼び出せます。
import { apiSlice } from '../api/apiSlice'
// This is the _same_ reference as `apiSlice`, but this has
// the TS types updated to include the injected endpoints
export const apiSliceWithUsers = apiSlice.injectEndpoints({
endpoints: builder => ({
getUsers: builder.query<User[], void>({
query: () => '/users'
})
})
})
export const { useGetUsersQuery } = apiSliceWithUsers
export const selectUsersResult = apiSliceWithUsers.endpoints.getUsers.select()
injectEndpoints()は元のAPIスライスオブジェクトを変更して追加のエンドポイント定義を加え、同じAPI参照を返します。加えて、injectEndpointsの戻り値には注入されたエンドポイントからの追加のTypeScript型が含まれます。
このため、更新されたTypeScript型を使用し、すべてが正しくコンパイルされるように、またどのバージョンのAPIスライスを使用しているかを明確にするため、新しい変数として別名で保存する必要があります。ここでは、元のapiSliceと区別するためにapiSliceWithUsersと呼びます。
現時点でgetUsersエンドポイントを参照している唯一のファイルは、エントリポイントファイルです(initiateサンクをディスパッチしています)。これを拡張されたAPIスライスをインポートするように更新する必要があります:
import { apiSliceWithUsers } from './features/users/usersSlice'
import { worker } from './api/server'
import './index.css'
// Wrap app rendering so we can wait for the mock API to initialize
async function start() {
// Start our mock API server
await worker.start({ onUnhandledRequest: 'bypass' })
store.dispatch(apiSliceWithUsers.endpoints.getUsers.initiate())
const root = createRoot(document.getElementById('root')!)
root.render(
<React.StrictMode>
<Provider store={store}>
<App />
</Provider>
</React.StrictMode>
)
}
別の方法として、スライスファイルから特定のエンドポイント自体をエクスポートすることもできます(スライスでアクションクリエイターを扱ったのと同じ方法です)。
レスポンスデータの操作
これまで、すべてのクエリエンドポイントはサーバーからのレスポンスデータをそのままの形式で保存してきました。getPostsとgetUsersは両方ともサーバーが配列を返すことを期待し、getPostは個々のPostオブジェクトをボディとして期待します。
クライアントがサーバーレスポンスからデータの一部を抽出したり、キャッシュする前に何らかの形でデータを変換する必要があるのは一般的なケースです。例えば、/getPostリクエストが{post: {id}}のようなネストされたデータをボディとして返す場合はどうでしょうか?
概念的にはいくつかの対応方法があります。1つのオプションはresponseData.postフィールドを抽出し、ボディ全体ではなくその部分をキャッシュに保存する方法です。もう1つはレスポンスデータ全体をキャッシュに保存しつつ、コンポーネントが必要な特定の部分だけを指定する方法です。
レスポンスの変換
エンドポイントはtransformResponseハンドラーを定義でき、サーバーから受信したデータをキャッシュ前に抽出または修正できます。例えばgetPostが{post: {id}}を返す場合、transformResponse: (responseData) => responseData.postと設定することで、レスポンス全体ではなく実際のPostオブジェクトのみをキャッシュできます。
パート6: パフォーマンスと正規化では、データを正規化された構造で保存することが有用な理由について説明しました。特に、IDに基づいてアイテムを検索・更新できるため、配列をループして目的のアイテムを見つける必要がなくなります。
現在、selectUserByIdセレクタはキャッシュされたユーザー配列をループして適切なUserオブジェクトを見つける必要があります。レスポンスデータを正規化された形式で保存するように変換すれば、IDで直接ユーザーを検索できるよう簡略化できます。
以前はusersSliceでcreateEntityAdapterを使用して正規化されたユーザーデータを管理していました。createEntityAdapterをextendedApiSliceに統合し、実際にデータがキャッシュされる前にcreateEntityAdapterでデータを変換できます。元々用意していたusersAdapterの行のコメントを解除し、その更新関数とセレクタを再び使用します。
import {
createSelector,
createEntityAdapter,
EntityState
} from '@reduxjs/toolkit'
import type { RootState } from '@/app/store'
import { apiSlice } from '@/features/api/apiSlice'
import { selectCurrentUsername } from '@/features/auth/authSlice'
export interface User {
id: string
name: string
}
const usersAdapter = createEntityAdapter<User>()
const initialState = usersAdapter.getInitialState()
// This is the _same_ reference as `apiSlice`, but this has
// the TS types updated to include the injected endpoints
export const apiSliceWithUsers = apiSlice.injectEndpoints({
endpoints: builder => ({
getUsers: builder.query<EntityState<User, string>, void>({
query: () => '/users',
transformResponse(res: User[]) {
// Create a normalized state object containing all the user items
return usersAdapter.setAll(initialState, res)
}
})
})
})
export const { useGetUsersQuery } = apiSliceWithUsers
// Calling `someEndpoint.select(someArg)` generates a new selector that will return
// the query result object for a query with those parameters.
// To generate a selector for a specific query argument, call `select(theQueryArg)`.
// In this case, the users query has no params, so we don't pass anything to select()
export const selectUsersResult = apiSliceWithUsers.endpoints.getUsers.select()
const selectUsersData = createSelector(
selectUsersResult,
// Fall back to the empty entity state if no response yet.
result => result.data ?? initialState
)
export const selectCurrentUser = (state: RootState) => {
const currentUsername = selectCurrentUsername(state)
if (currentUsername) {
return selectUserById(state, currentUsername)
}
}
export const { selectAll: selectAllUsers, selectById: selectUserById } =
usersAdapter.getSelectors(selectUsersData)
getUsersエンドポイントにtransformResponseオプションを追加しました。このオプションはレスポンスデータ全体を引数として受け取り(この場合はUser[]配列)、キャッシュする実際のデータを返します。usersAdapter.setAll(initialState, responseData)を呼び出すことで、受信した全アイテムを含む標準的な正規化データ構造{ids: [], entities: {}}を返します。キャッシュエントリのdataフィールドの内容としてEntityState<User, string>データを返すようTSに明示する必要があります。
adapter.getSelectors()関数には、正規化データの場所を知るための「入力セレクタ」を指定する必要があります。データはRTK Queryキャッシュリデューサ内にネストされているため、キャッシュ状態から適切なフィールドを選択します。一貫性を保つため、データ未取得時には初期の空の正規化状態にフォールバックするselectUsersDataセレクタを作成できます。
正規化キャッシュ vs ドキュメントキャッシュ
ここで一旦立ち止まり、行った変更の内容とその重要性について考察する価値があります。
Apolloなどのデータ取得ライブラリに関連して「正規化キャッシュ」という用語を耳にしたことがあるかもしれません。RTK Queryは「正規化キャッシュ」ではなく「ドキュメントキャッシュ」アプローチを採用していることを理解することが重要です。
完全な正規化キャッシュは、アイテムタイプとIDに基づいて_すべての_クエリ間で類似アイテムの重複排除を試みます。例として、getTodosとgetTodoエンドポイントを持つAPIスライスがあり、コンポーネントが次のクエリを実行するとします:
-
getTodos() -
getTodos({filter: 'odd'}) -
getTodo({id: 1})
各クエリ結果には{id: 1}のようなTodoオブジェクトが含まれます。
完全な正規化キャッシュでは、このTodoオブジェクトの単一コピーのみが保存されます。しかしRTK Queryは各クエリ結果を独立してキャッシュに保存します。その結果、このTodoの3つの別々のコピーがReduxストアにキャッシュされます。ただし、全エンドポイントが一貫して同じタグ(例:{type: 'Todo', id: 1})を提供している場合、そのタグを無効化すると一致する全エンドポイントが一貫性のためにデータを再取得します。
RTK Queryは意図的に複数リクエスト間で同一アイテムを重複排除するキャッシュを実装していません。これには次の理由があります:
-
クエリ全体で共有される完全な正規化キャッシュは解決が_極めて困難_な問題である
-
現時点でこの問題を解決する時間・リソース・意図がない
-
多くのケースでは、無効化時に単純にデータを再取得する方が効果的で理解しやすい
-
RTKQの主目的は「データ取得」という一般的なユースケースの解決であり、これは多くの開発者にとって重大な課題である
このケースでは、getUsersエンドポイントのレスポンスデータを正規化しただけです。つまり{[id]: value}形式のルックアップテーブルとして保存しています。しかしこれは「正規化されたキャッシュ」とは異なります。複数のエンドポイントやリクエスト間で結果を重複排除しているわけではなく、単一のレスポンスの保存方法を変換しただけです。
結果から値の選択
古いpostsSliceから読み取っている最後のコンポーネントは<UserPage>で、現在のユーザーに基づいて投稿リストをフィルタリングします。useGetPostsQuery()で投稿全体リストを取得し、useMemo内でソートするなどコンポーネント内で変換できることは既に見てきました。クエリフックはselectFromResultオプションを提供することでキャッシュ状態の一部を選択し、選択した部分が変更された時のみ再レンダリングする機能も提供します。
useQueryフックは常にキャッシュキー引数を第一引数に取ります。フックオプションを指定する必要がある場合、それは必ず第二引数として渡す必要があります(例:useSomeQuery(cacheKey, options))。今回のケースでは、getUsersエンドポイントには実際のキャッシュキー引数がありません。意味的にはundefinedのキャッシュキーと同じです。そのためフックにオプションを渡すにはuseGetUsersQuery(undefined, options)と呼び出す必要があります。
selectFromResultを使用して<UserPage>にキャッシュからフィルタリングされた投稿リストのみを読み取らせることができます。ただし、selectFromResultが不要な再レンダリングを避けるには、抽出するデータが適切にメモ化されていることを保証する必要があります。これを実現するには、<UserPage>コンポーネントがレンダリングのたびに再利用できる新しいセレクターインスタンスを作成し、セレクターが入力に基づいて結果をメモ化できるようにします。
import { Link, useParams } from 'react-router-dom'
import { createSelector } from '@reduxjs/toolkit'
import type { TypedUseQueryStateResult } from '@reduxjs/toolkit/query/react'
import { useAppSelector } from '@/app/hooks'
import { useGetPostsQuery, Post } from '@/features/api/apiSlice'
import { selectUserById } from './usersSlice'
// Create a TS type that represents "the result value passed
// into the `selectFromResult` function for this hook"
type GetPostsSelectFromResultArg = TypedUseQueryStateResult<Post[], any, any>
const selectPostsForUser = createSelector(
(res: GetPostsSelectFromResultArg) => res.data,
(res: GetPostsSelectFromResultArg, userId: string) => userId,
(data, userId) => data?.filter(post => post.user === userId)
)
export const UserPage = () => {
const { userId } = useParams()
const user = useAppSelector(state => selectUserById(state, userId!))
// Use the same posts query, but extract only part of its data
const { postsForUser } = useGetPostsQuery(undefined, {
selectFromResult: result => ({
// Optional: Include all of the existing result fields like `isFetching`
...result,
// Include a field called `postsForUser` in the result object,
// which will be a filtered list of posts
postsForUser: selectPostsForUser(result, userId!)
})
})
// omit rendering logic
}
ここで作成したメモ化セレクター関数には重要な違いがあります。通常、セレクターはRedux全体のstateを第一引数に期待し、stateから値を抽出または導出します。しかし今回扱っているのはキャッシュに保持されている「結果」値だけです。結果オブジェクトには必要な実際の値を持つdataフィールドと、いくつかのリクエストメタデータフィールドが含まれています。
このセレクターは通常のRootStateタイプとは異なるものを第一引数として受け取るため、TSにその結果値の形状を伝える必要があります。RTK QueryパッケージはTypedUseQueryStateResultというTSタイプをエクスポートしており、これは「useQueryフックの戻りオブジェクトのタイプ」を表します。このタイプを使用して、結果にPost[]配列が含まれることを宣言し、そのタイプを使用してセレクターを定義できます。
RTK 2.xおよびReselect 5.x以降では、メモ化セレクターは無限のキャッシュサイズを持つため、引数を変更しても以前のメモ化結果を保持できます。RTK 1.xまたはReselect 4.xを使用している場合、メモ化セレクターのデフォルトキャッシュサイズは1であることに注意してください。IDのような異なる引数が渡されたときにセレクターが一貫してメモ化するようにするには、コンポーネントごとに一意のセレクターインスタンスを作成する必要があります。
selectFromResultコールバックは、元のリクエストメタデータとサーバーからのdataを含むresultオブジェクトを受け取り、抽出または導出された値を返す必要があります。クエリフックはここで返されるものに追加のrefetchメソッドを追加するため、selectFromResultは常に必要なフィールドを含むオブジェクトを返す必要があります。
resultはReduxストアに保持されているため、変更できません。新しいオブジェクトを返す必要があります。クエリフックはこの返されたオブジェクトに対して「浅い」比較を行い、フィールドのいずれかが変更された場合にのみコンポーネントを再レンダリングします。このコンポーネントで不要なメタデータフラグの残りを完全に省略することで、再レンダリングを最適化できます。必要な場合は、元のresult値をスプレッドして出力に含めることができます。
この場合、フィールド名を postsForUser とし、フックの結果からこの新しいフィールドを分割代入できます。selectPostsForUser(result, userId) を毎回呼び出すことで、フィルタリングされた配列がメモ化され、取得データやユーザーIDが変更された場合のみ再計算されます。
データ変換手法の比較
これまでに、レスポンスを変換する3つの異なる管理手法を見てきました:
-
キャッシュに元のレスポンスを保持し、コンポーネント内で全結果を読み取って値を導出する
-
キャッシュに元のレスポンスを保持し、
selectFromResultで導出された結果を読み取る -
キャッシュに保存する前にレスポンスを変換する
これらの各アプローチは状況に応じて有用です。以下のような場合に使用を検討するとよいでしょう:
-
transformResponse: エンドポイントのすべての利用者が特定のフォーマットを必要とする場合(例:IDによる高速検索を可能にするレスポンスの正規化) -
selectFromResult: エンドポイントの一部の利用者がフィルタリングされたリストなど部分的なデータのみを必要とする場合 -
コンポーネント単位 /
useMemo: 特定のコンポーネントのみがキャッシュデータの変換を必要とする場合
高度なキャッシュ更新
投稿とユーザーデータの更新が完了したため、残っているのはリアクションと通知の処理です。これらをRTK Queryに移行することで、RTK Queryのキャッシュデータを操作する高度なテクニックを試す機会が得られ、より良いユーザー体験を提供できるようになります。
リアクションの永続化
当初、リアクションはクライアント側でのみ追跡し、サーバーに永続化していませんでした。新しい addReaction ミューテーションを追加し、ユーザーがリアクションボタンをクリックするたびに、対応する Post をサーバー上で更新しましょう。
export const apiSlice = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
tagTypes: ['Post'],
endpoints: builder => ({
// omit other endpoints
addReaction: builder.mutation<
Post,
{ postId: string; reaction: ReactionName }
>({
query: ({ postId, reaction }) => ({
url: `posts/${postId}/reactions`,
method: 'POST',
// In a real app, we'd probably need to base this on user ID somehow
// so that a user can't do the same reaction more than once
body: { reaction }
}),
invalidatesTags: (result, error, arg) => [
{ type: 'Post', id: arg.postId }
]
})
})
})
export const {
useGetPostsQuery,
useGetPostQuery,
useAddNewPostMutation,
useEditPostMutation,
useAddReactionMutation
} = apiSlice
他のミューテーションと同様に、パラメータを受け取りリクエストボディにデータを含めてサーバーにリクエストします。このサンプルアプリは小規模なので、リアクション名のみを渡し、サーバー側で該当投稿の対応するリアクションタイプのカウンターをインクリメントさせます。
クライアント側でデータ変更を反映するにはこの投稿を再取得する必要があるため、IDに基づいて特定の Post エントリを無効化できます。
これで準備が整ったので、<ReactionButtons> を更新してこのミューテーションを使用しましょう。
import { useAddReactionMutation } from '@/features/api/apiSlice'
import type { Post, ReactionName } from './postsSlice'
const reactionEmoji: Record<ReactionName, string> = {
thumbsUp: '👍',
tada: '🎉',
heart: '❤️',
rocket: '🚀',
eyes: '👀'
}
interface ReactionButtonsProps {
post: Post
}
export const ReactionButtons = ({ post }: ReactionButtonsProps) => {
const [addReaction] = useAddReactionMutation()
const reactionButtons = Object.entries(reactionEmoji).map(
([stringName, emoji]) => {
// Ensure TS knows this is a _specific_ string type
const reaction = stringName as ReactionName
return (
<button
key={reaction}
type="button"
className="muted-button reaction-button"
onClick={() => {
addReaction({ postId: post.id, reaction })
}}
>
{emoji} {post.reactions[reaction]}
</button>
)
}
)
return <div>{reactionButtons}</div>
}
実際の動作を確認してみましょう!メインの <PostsList> に移動し、リアクションのいずれかをクリックして結果を観察します。
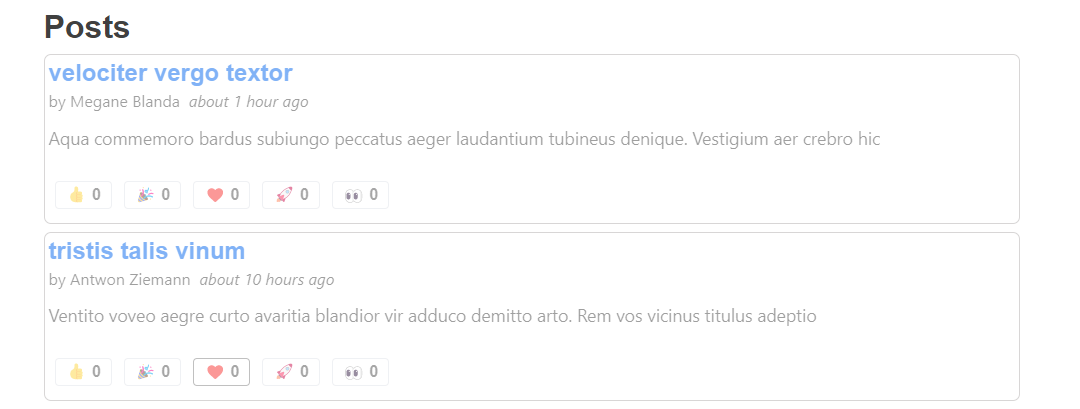
問題が発生しました。たった1つの投稿が更新されたという応答で投稿の全リストを再取得したため、<PostsList> コンポーネント全体がグレーアウトされました。モックAPIサーバーは応答前に2秒の遅延が設定されているため意図的に目立ちますが、応答が速い場合でもこれは良いユーザー体験とは言えません。
リアクションの楽観的更新
リアクション追加のような小さな更新では、投稿の全リストを再取得する必要はおそらくありません。代わりに、サーバーで起こると予想される内容に一致するよう、クライアント上の既存キャッシュデータを更新できます。また、キャッシュを即座に更新すれば、ユーザーは応答を待たずにボタンクリック時に即時フィードバックを得られます。クライアント状態を即座に更新するこの手法は「楽観的更新 (optimistic update)」と呼ばれ、Webアプリで一般的なパターンです。
RTK Queryにはクライアントサイドキャッシュを直接更新するユーティリティが含まれています。これはRTK Queryの**「リクエストライフサイクル」メソッド**と組み合わせて楽観的更新を実装できます。
キャッシュ更新ユーティリティ
APIスライスにはapi.util配下に追加メソッドが用意されています。これにはキャッシュを操作するサンクが含まれており、upsertQueryDataでキャッシュエントリの追加・置換、updateQueryDataでキャッシュエントリの変更が可能です。これらはサンクであるため、dispatchにアクセスできる場所であればどこでも使用できます。
特にupdateQueryDataユーティリティサンクは3つの引数を取ります:更新対象のエンドポイント名、対象キャッシュエントリを特定するためのキャッシュキー引数、キャッシュデータを更新するコールバック関数です。updateQueryDataはImmerを使用しているため、createSliceと同様にドラフト化されたキャッシュデータを「ミューテート」できます:
dispatch(
apiSlice.util.updateQueryData(endpointName, queryArg, draft => {
// mutate `draft` here like you would in a reducer
draft.value = 123
})
)
updateQueryDataは変更内容のパッチ差分を含むアクションオブジェクトを生成します。このアクションをディスパッチすると、dispatchの戻り値としてpatchResultオブジェクトが得られます。patchResult.undo()を呼び出すと、パッチ差分の変更を元に戻すアクションが自動的にディスパッチされます。
onQueryStartedライフサイクル
最初に紹介するライフサイクルメソッドはonQueryStartedです。このオプションはクエリとミューテーションの両方で利用可能です。
これを指定すると、新しいリクエストが送出されるたびにonQueryStartedが呼び出されます。これによりリクエストに応じた追加ロジックを実行できます。
非同期サンクやリスナーエフェクトと同様に、onQueryStartedコールバックは第一引数にリクエストのクエリarg値を受け取り、第二引数にlifecycleApiオブジェクトを受け取ります。lifecycleApiにはcreateAsyncThunkと同じ{dispatch, getState, extra, requestId}値が含まれます。さらに、このライフサイクル固有のフィールドが追加されています。最も重要なのはlifecycleApi.queryFulfilledで、リクエストが完了すると解決され、リクエスト結果に基づいてfulfillまたはrejectするPromiseです。
楽観的更新の実装
onQueryStartedライフサイクル内で更新ユーティリティを使用することで、「楽観的更新」(リクエスト完了前にキャッシュを更新)または「悲観的更新」(リクエスト完了後にキャッシュを更新)を実装できます。
楽観的更新を実装するには、getPostsキャッシュ内の特定のPostエントリを見つけ、リアクションカウンターをインクリメントするよう「ミューテート」します。また、同じ概念的な個別Postオブジェクトが、その投稿IDに対するgetPostキャッシュにも存在する可能性があるため、存在すればそちらのキャッシュエントリも更新する必要があります。
デフォルトではリクエストが成功することを想定しています。リクエストが失敗した場合、await lifecycleApi.queryFulfilledで失敗をキャッチし、パッチ変更を元に戻して楽観的更新をロールバックできます。
export const apiSlice = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
tagTypes: ['Post'],
endpoints: builder => ({
// omit other endpoints
addReaction: builder.mutation<
Post,
{ postId: string; reaction: ReactionName }
>({
query: ({ postId, reaction }) => ({
url: `posts/${postId}/reactions`,
method: 'POST',
// In a real app, we'd probably need to base this on user ID somehow
// so that a user can't do the same reaction more than once
body: { reaction }
}),
// The `invalidatesTags` line has been removed,
// since we're now doing optimistic updates
async onQueryStarted({ postId, reaction }, lifecycleApi) {
// `updateQueryData` requires the endpoint name and cache key arguments,
// so it knows which piece of cache state to update
const getPostsPatchResult = lifecycleApi.dispatch(
apiSlice.util.updateQueryData('getPosts', undefined, draft => {
// The `draft` is Immer-wrapped and can be "mutated" like in createSlice
const post = draft.find(post => post.id === postId)
if (post) {
post.reactions[reaction]++
}
})
)
// We also have another copy of the same data in the `getPost` cache
// entry for this post ID, so we need to update that as well
const getPostPatchResult = lifecycleApi.dispatch(
apiSlice.util.updateQueryData('getPost', postId, draft => {
draft.reactions[reaction]++
})
)
try {
await lifecycleApi.queryFulfilled
} catch {
getPostsPatchResult.undo()
getPostPatchResult.undo()
}
}
})
})
})
このケースでは、リアクションボタンをクリック時に投稿を再取得したくないため、先ほど追加したinvalidatesTags行も削除しています。
これで、リアクションボタンを素早く複数回クリックすると、UI上で数字が毎回インクリメントされるはずです。Networkタブを見ると、各リクエストが個別にサーバーに送出されていることも確認できます。
ミューテーションリクエストのサーバー応答には、一時的なクライアントサイドIDを置き換える最終的なアイテムIDなど、意味のあるデータが含まれる場合があります。先にconst res = await lifecycleApi.queryFulfilledを実行すれば、その後のレスポンスデータを使用して「悲観的更新」としてキャッシュを更新できます。
通知のためのストリーミング更新
最後の機能は通知タブです。第6部で最初にこの機能を構築した際、「実際のアプリケーションでは、何かイベントが発生するたびにサーバーがクライアントに更新をプッシュする」と説明しました。当初は「通知を更新」ボタンを追加し、HTTP GETリクエストで通知エントリを取得することでこの機能を模擬していました。
一般的なアプリケーションでは、サーバーからデータを取得するために初期リクエストを行った後、Websocket接続を開いて追加の更新をリアルタイムで受信します。RTK Queryのライフサイクルメソッドは、キャッシュされたデータに対するこの種の「ストリーミング更新」を実装する余地を提供します。
既にonQueryStartedライフサイクルを通じて楽観的(または悲観的)更新を実装する方法を見てきました。さらにRTK QueryはonCacheEntryAddedエンドポイントライフサイクルハンドラーを提供しており、ストリーミング更新を実装するのに最適な場所です。この機能を活用して、通知管理をより現実的なアプローチで実装します。
onCacheEntryAddedライフサイクル
onQueryStartedと同様に、onCacheEntryAddedライフサイクルメソッドはクエリとミューテーションの両方で利用可能です。
onCacheEntryAddedは新しいキャッシュエントリ(エンドポイント+シリアライズされたクエリ引数)がキャッシュに追加されるたびに呼び出されます。これはリクエストが発生するたびに実行されるonQueryStartedよりも実行頻度が低いことを意味します。
onQueryStartedと同様に、onCacheEntryAddedは2つのパラメータを受け取ります。第1引数は通常のクエリargs値です。第2引数は若干異なるlifecycleApiオブジェクトで、{dispatch, getState, extra, requestId}プロパティに加え、updateCachedDataユーティリティを備えています。これは、適切なエンドポイント名とクエリ引数を既に認識しており、ディスパッチ処理も代行するapi.util.updateQueryDataの代替形式です。
さらに待機可能な2つの追加のPromiseがあります:
-
cacheDataLoaded: 最初に受信したキャッシュ値で解決され、通常はさらなるロジックを実行する前に実際の値がキャッシュに存在するのを待つために使用されます -
cacheEntryRemoved: このキャッシュエントリが削除されたときに解決します (つまり、サブスクライバーが存在しなくなったかつキャッシュエントリがガベージコレクションされたとき)
データのサブスクライバーが1人以上アクティブな限り、キャッシュエントリは保持されます。サブスクライバー数が0になりキャッシュ有効期限が切れると、キャッシュエントリは削除されcacheEntryRemovedが解決します。典型的な使用パターンは:
-
即座に
await cacheDataLoadedする -
Websocketのようなサーバーサイドデータサブスクリプションを作成する
-
更新を受信したら
updateCachedDataを使用してキャッシュ値を更新する -
最後に
await cacheEntryRemovedする -
その後サブスクリプションをクリーンアップする
これによりonCacheEntryAddedは、UIが特定のデータを必要とする限り継続すべき長時間実行ロジックを配置するのに適した場所となります。良い例は、チャットチャンネルの初期メッセージを取得し、Websocketサブスクリプションで追加メッセージをリアルタイム受信し、ユーザーがチャンネルを閉じたときにWebsocketを切断するチャットアプリです。
通知の取得
この作業をいくつかのステップに分けて進めます。
まず通知用の新しいエンドポイントを設定し、fetchNotificationsWebsocketサンクの代替を追加して、モックバックエンドがHTTPリクエストではなくWebsocket経由で通知を送信するようにします。
getUsersと同様にnotificationsSliceでgetNotificationsエンドポイントをインジェクトします(可能であることを示すため)。
import { createEntityAdapter, createSlice } from '@reduxjs/toolkit'
import { client } from '@/api/client'
import { forceGenerateNotifications } from '@/api/server'
import type { AppThunk, RootState } from '@/app/store'
import { createAppAsyncThunk } from '@/app/withTypes'
import { apiSlice } from '@/features/api/apiSlice'
// omit types and `fetchNotifications` thunk
export const apiSliceWithNotifications = apiSlice.injectEndpoints({
endpoints: builder => ({
getNotifications: builder.query<ServerNotification[], void>({
query: () => '/notifications'
})
})
})
export const { useGetNotificationsQuery } = apiSliceWithNotifications
getNotificationsは標準的なクエリエンドポイントで、サーバーから受信したServerNotificationオブジェクトを保存します。
次に、<Navbar> で新しいクエリフックを使用して通知を自動的に取得します。ただし、これにより返されるのは ServerNotification オブジェクトのみで、追加の {read, isNew} フィールドを持つ ClientNotification オブジェクトではありません。そのため、一時的に notification.new のチェックを無効にする必要があります。
// omit other imports
import { allNotificationsRead, useGetNotificationsQuery } from './notificationsSlice'
export const NotificationsList = () => {
const dispatch = useAppDispatch()
const { data: notifications = [] } = useGetNotificationsQuery()
useLayoutEffect(() => {
dispatch(allNotificationsRead())
})
const renderedNotifications = notifications.map((notification) => {
const notificationClassname = classnames('notification', {
// new: notification.isNew,
})
}
// omit rendering
}
「Notifications」タブに移動すると、いくつかのエントリが表示されますが、新規通知を示す色付けはされません。一方、「Refresh Notifications」ボタンをクリックすると「未読通知」カウンターが増加し続けます。これには2つの理由があります:
- ボタンが従来の
fetchNotificationsサンクをトリガーし、state.notificationsスライスにエントリを保存している <NotificationsList>コンポーネントが再レンダリングされない(state.notificationsスライスではなくuseGetNotificationsQueryフックのキャッシュデータに依存しているため) 結果としてuseLayoutEffectが実行されず、allNotificationsReadもディスパッチされません。
クライアントサイド状態の追跡
次のステップは、通知の「既読」ステータス追跡方法の再検討です。
以前は fetchNotifications サンクから取得した ServerNotification オブジェクトにリデューサーで {read, isNew} フィールドを追加していました。現在は RTK Query キャッシュに ServerNotification オブジェクトを直接保存しています。
手動キャッシュ更新を追加することも可能です。transformResponse で追加フィールドを付与し、ユーザーが通知を閲覧する際にキャッシュを変更できます。
代わりに、既存のアプローチを発展させた別の方法を試します:notificationsSlice 内で既読ステータスを管理する方法です。
概念的には、各通知アイテムの {read, isNew} ステータスを追跡することが目的です。クエリフックが通知を取得したタイミングと通知IDを把握できるなら、スライス内で対応する「メタデータ」エントリを保持できます。
幸い、これは可能です!RTK Query は createAsyncThunk などの標準 Redux Toolkit コンポーネントで構築されているため、リクエスト完了時に結果を含む fulfilled アクションをディスパッチします。notificationsSlice でこのアクションをリッスンするには、createSlice.extraReducers を使用します。
しかし何をリッスンすべきでしょうか?RTKQエンドポイントの場合、asyncThunk.fulfilled/pending アクションクリエーターに直接アクセスできないため、builder.addCase() に渡せません。
RTK Query エンドポイントは matchFulfilled マッチャー関数を提供しており、extraReducers 内でエンドポイントの fulfilled アクションをリッスンできます(builder.addCase() から builder.addMatcher() への変更が必要です)。
そこで ClientNotification を NotificationMetadata 型に変更し、getNotifications クエリアクションをリッスンして、通知全体ではなく「メタデータのみ」のオブジェクトをスライスに保存します。
これに伴い、明確化のため notificationsAdapter を metadataAdapter にリネームし、notification 変数参照をすべて metadata に置換します(変更量は多いものの、主に変数名の変更です)。
エンティティアダプターの selectEntities セレクターを selectMetadataEntities としてエクスポートします。UIでメタデータオブジェクトをID検索する際、コンポーネント内でルックアップテーブルを利用可能にすると便利です。
// omit imports and thunks
// Replaces `ClientNotification`, since we just need these fields
export interface NotificationMetadata {
// Add an `id` field, since this is now a standalone object
id: string
read: boolean
isNew: boolean
}
export const fetchNotifications = createAppAsyncThunk(
'notifications/fetchNotifications',
async (_unused, thunkApi) => {
// Deleted timestamp lookups - we're about to remove this thunk anyway
const response = await client.get<ServerNotification[]>(
`/fakeApi/notifications`
)
return response.data
}
)
// Renamed from `notificationsAdapter`, and we don't need sorting
const metadataAdapter = createEntityAdapter<NotificationMetadata>()
const initialState = metadataAdapter.getInitialState()
const notificationsSlice = createSlice({
name: 'notifications',
initialState,
reducers: {
allNotificationsRead(state) {
// Rename to `metadata`
Object.values(state.entities).forEach(metadata => {
metadata.read = true
})
}
},
extraReducers(builder) {
// Listen for the endpoint `matchFulfilled` action with `addMatcher`
builder.addMatcher(
apiSliceWithNotifications.endpoints.getNotifications.matchFulfilled,
(state, action) => {
// Add client-side metadata for tracking new notifications
const notificationsMetadata: NotificationMetadata[] =
action.payload.map(notification => ({
// Give the metadata object the same ID as the notification
id: notification.id,
read: false,
isNew: true
}))
// Rename to `metadata`
Object.values(state.entities).forEach(metadata => {
// Any notifications we've read are no longer new
metadata.isNew = !metadata.read
})
metadataAdapter.upsertMany(state, notificationsMetadata)
}
)
}
})
export const { allNotificationsRead } = notificationsSlice.actions
export default notificationsSlice.reducer
// Rename the selector
export const {
selectAll: selectAllNotificationsMetadata,
selectEntities: selectMetadataEntities
} = metadataAdapter.getSelectors(
(state: RootState) => state.notifications
)
export const selectUnreadNotificationsCount = (state: RootState) => {
const allMetadata = selectAllNotificationsMetadata(state)
const unreadNotifications = allMetadata.filter(metadata => !metadata.read)
return unreadNotifications.length
}
このメタデータルックアップテーブルを <NotificationsList> で読み込み、レンダリングする各通知に対応するメタデータオブジェクトを検索し、isNew チェックを再有効化して適切なスタイルを表示します:
import { allNotificationsRead, useGetNotificationsQuery, selectMetadataEntities } from './notificationsSlice'
export const NotificationsList = () => {
const dispatch = useAppDispatch()
const { data: notifications = [] } = useGetNotificationsQuery()
const notificationsMetadata = useAppSelector(selectMetadataEntities)
useLayoutEffect(() => {
dispatch(allNotificationsRead())
})
const renderedNotifications = notifications.map((notification) => {
// Get the metadata object matching this notification
const metadata = notificationsMetadata[notification.id]
const notificationClassname = classnames('notification', {
// re-enable the `isNew` check for styling
new: metadata.isNew,
})
// omit rendering
}
}
「Notifications」タブを確認すると、新規通知は正しくスタイルされています...しかし追加通知は表示されず、既読マークも付きません。
WebSocket経由での通知プッシュ
サーバープッシュによる通知取得への移行を完了するには、さらにいくつかの手順が必要です。
次のステップでは、「通知を更新」ボタンの動作を、HTTPリクエスト経由で取得する非同期Thunkのディスパッチから、モックバックエンドにWebSocket経由で通知を送信させるように変更します。
src/api/server.tsファイルには、モックHTTPサーバーと同様に、すでに設定済みのモックWebSocketサーバーがあります。実際のバックエンド(や他のユーザー)がないため、新しい通知をいつ送信するかをモックサーバーに手動で指示する必要があります。これを実現するために、server.tsはforceGenerateNotifications関数をエクスポートしており、この関数を呼び出すとバックエンドがWebSocket経由で通知エントリをプッシュします。
既存のfetchNotifications非同期ThunkをfetchNotificationsWebsocketThunkに置き換えます。fetchNotificationsWebsocketは既存のfetchNotifications非同期Thunkと同様の処理を行いますが、実際のHTTPリクエストを行わないため、await呼び出しや返すペイロードはありません。サーバーサイドプッシュ通知を模倣するためにserver.tsがエクスポートした関数を呼び出すだけです。
このため、fetchNotificationsWebsocketはcreateAsyncThunkを必要としません。通常の手書きThunkとして実装できるため、AppThunk型を使用してThunk関数の型を正しく記述し、(dispatch, getState)に適切な型を付与できます。
「最新タイムスタンプ」チェックを実装するには、通知キャッシュエントリから読み取るセレクターを追加する必要があります。ユーザースライスで見たのと同じパターンを使用します。
import {
createEntityAdapter,
createSlice,
createSelector
} from '@reduxjs/toolkit'
import { forceGenerateNotifications } from '@/api/server'
import type { AppThunk, RootState } from '@/app/store'
import { apiSlice } from '@/features/api/apiSlice'
// omit types and API slice setup
export const { useGetNotificationsQuery } = apiSliceWithNotifications
export const fetchNotificationsWebsocket =
(): AppThunk => (dispatch, getState) => {
const allNotifications = selectNotificationsData(getState())
const [latestNotification] = allNotifications
const latestTimestamp = latestNotification?.date ?? ''
// Hardcode a call to the mock server to simulate a server push scenario over websockets
forceGenerateNotifications(latestTimestamp)
}
const emptyNotifications: ServerNotification[] = []
export const selectNotificationsResult =
apiSliceWithNotifications.endpoints.getNotifications.select()
const selectNotificationsData = createSelector(
selectNotificationsResult,
notificationsResult => notificationsResult.data ?? emptyNotifications
)
// omit slice and selectors
次に、<Navbar>が代わりにfetchNotificationsWebsocketをディスパッチするように変更します:
import {
fetchNotificationsWebsocket,
selectUnreadNotificationsCount,
} from '@/features/notifications/notificationsSlice'
import { selectCurrentUser } from '@/features/users/usersSlice'
import { UserIcon } from './UserIcon'
export const Navbar = () => {
// omit hooks
if (isLoggedIn) {
const onLogoutClicked = () => {
dispatch(logout())
}
const fetchNewNotifications = () => {
dispatch(fetchNotificationsWebsocket())
}
ほぼ完了です!RTK Query経由で初期通知を取得し、クライアントサイドで既読状態を追跡し、WebSocket経由で新しい通知をプッシュするための基盤が整いました。しかし、現時点で「通知を更新」ボタンをクリックするとエラーが発生します。WebSocket処理がまだ実装されていないためです!
では、実際のストリーミング更新ロジックを実装しましょう。
ストリーミング更新の実装
このアプリでは、ユーザーがログインしたら直ちに通知をチェックし、以降のすべての通知更新をリッスンし続けることを想定しています。ユーザーがログアウトしたら、リッスンを停止する必要があります。
<Navbar>はユーザーログイン後にのみレンダリングされ、常に表示され続けることが分かっています。したがって、ここでキャッシュサブスクリプションを維持するのに適しています。このコンポーネントでuseGetNotificationsQuery()フックをレンダリングすることで実現できます。
// omit other imports
import {
fetchNotificationsWebsocket,
selectUnreadNotificationsCount,
useGetNotificationsQuery
} from '@/features/notifications/notificationsSlice'
export const Navbar = () => {
const dispatch = useAppDispatch()
const user = useAppSelector(selectCurrentUser)
// Trigger initial fetch of notifications and keep the websocket open to receive updates
useGetNotificationsQuery()
// omit rest of the component
}
最後のステップは、getNotificationsエンドポイントにonCacheEntryAddedライフサイクルハンドラーを追加し、WebSocketを操作するロジックを実装することです。
このケースでは、新しいWebSocketを作成し、ソケットからの受信メッセージをサブスクライブし、それらのメッセージから通知を読み取り、RTKQキャッシュエントリを追加データで更新します。これは概念的にはonQueryStartedでの楽観的更新と似ています。
ここで直面する別の問題があります。WebSocket経由で通知を受信している場合、明示的な「リクエスト成功」アクションはディスパッチされませんが、受信したすべての通知に対して新しいメタデータエントリを作成する必要があります。
この問題に対処するため、「通知をさらに受信した」ことを通知する専用のReduxアクションタイプを作成し、WebSocketハンドラー内からこのアクションをディスパッチします。その後、notificationsSliceを更新して、エンドポイントアクションとこの新しいアクションの両方をisAnyOfマッチャーユーティリティでリッスンし、両ケースで同じメタデータロジックを実行できるようにします。
import {
createEntityAdapter,
createSlice,
createSelector,
createAction,
isAnyOf
} from '@reduxjs/toolkit'
// omit imports and other code
const notificationsReceived = createAction<ServerNotification[]>('notifications/notificationsReceived')
export const apiSliceWithNotifications = apiSlice.injectEndpoints({
endpoints: builder => ({
getNotifications: builder.query<ServerNotification[], void>({
query: () => '/notifications',
async onCacheEntryAdded(arg, lifecycleApi) {
// create a websocket connection when the cache subscription starts
const ws = new WebSocket('ws://localhost')
try {
// wait for the initial query to resolve before proceeding
await lifecycleApi.cacheDataLoaded
// when data is received from the socket connection to the server,
// update our query result with the received message
const listener = (event: MessageEvent<string>) => {
const message: {
type: 'notifications'
payload: ServerNotification[]
} = JSON.parse(event.data)
switch (message.type) {
case 'notifications': {
lifecycleApi.updateCachedData(draft => {
// Insert all received notifications from the websocket
// into the existing RTKQ cache array
draft.push(...message.payload)
draft.sort((a, b) => b.date.localeCompare(a.date))
})
// Dispatch an additional action so we can track "read" state
lifecycleApi.dispatch(notificationsReceived(message.payload))
break
}
default:
break
}
}
ws.addEventListener('message', listener)
} catch {
// no-op in case `cacheEntryRemoved` resolves before `cacheDataLoaded`,
// in which case `cacheDataLoaded` will throw
}
// cacheEntryRemoved will resolve when the cache subscription is no longer active
await lifecycleApi.cacheEntryRemoved
// perform cleanup steps once the `cacheEntryRemoved` promise resolves
ws.close()
}
})
})
})
export const { useGetNotificationsQuery } = apiSliceWithNotifications
const matchNotificationsReceived = isAnyOf(
notificationsReceived,
apiSliceWithNotifications.endpoints.getNotifications.matchFulfilled,
)
// omit other code
const notificationsSlice = createSlice({
name: 'notifications',
initialState,
reducers: { /* omit reducers */ },
extraReducers(builder) {
builder.addMatcher(matchNotificationsReceived, (state, action) => {
// omit logic
}
},
})
キャッシュエントリが追加されると、モックサーバーバックエンドに接続する新しいWebSocketインスタンスを作成します。
lifecycleApi.cacheDataLoadedプロミスが解決するのを待機します。これによりリクエストが完了し、実際のデータが利用可能になったことが分かります。
WebSocketからの着信メッセージをサブスクライブする必要があります。コールバックはWebSocketのMessageEventを受け取り、event.dataにはバックエンドから送信されたJSONシリアライズされた通知データが文字列として含まれています。
このメッセージを受信したら、内容をパースし、パースされたオブジェクトが対象のメッセージタイプと一致することを確認します。一致する場合、lifecycleApi.updateCachedData()を呼び出し、新しい通知を既存のキャッシュエントリに追加し、正しい順序で表示されるよう再ソートします。
最後に、lifecycleApi.cacheEntryRemovedプロミスを待機することで、WebSocketを閉じてクリーンアップするタイミングを把握できます。
ライフサイクルメソッド内でWebSocketを作成する必要はないことに注意してください。アプリの構造によっては、アプリ設定の早い段階で作成され、別のモジュールファイルやReduxミドルウェア内に存在する場合があります。重要なのは、onCacheEntryAddedライフサイクルを使用して、着信データの監視開始タイミング、結果のキャッシュへの挿入、キャッシュエントリ消失時のクリーンアップを制御することです。
以上です!これで「通知を更新」をクリックすると未読通知数が増加し、「通知」タブを開くと既読/未読通知が適切にハイライト表示されるはずです。
クリーンアップ
最終ステップとして追加のクリーンアップを行います。postsSlice.ts内の実際のcreateSlice呼び出しは不要になったので、スライスオブジェクトと関連セレクター+型を削除し、ReduxストアからpostsReducerを削除します。addPostsListeners関数と型は合理的な場所なので残します。
学んだこと
これでアプリケーションのRTK Queryへの移行が完了しました!すべてのデータ取得がRTKQに切り替わり、楽観的更新とストリーミング更新によりユーザーエクスペリエンスが向上しました。
見てきたように、RTK Queryはキャッシュデータ管理を制御する強力なオプションを備えています。すぐにすべてが必要になるわけではありませんが、特定のアプリケーション動作を実装するための柔軟性と重要な機能を提供します。
最後にアプリケーション全体の動作を確認しましょう:
- キャッシュタグを詳細に指定してキャッシュ無効化を制御可能
- キャッシュタグは
'Post'または{type: 'Post', id}形式で指定 - エンドポイントは結果と引数キャッシュキーに基づきタグを提供/無効化可能
- キャッシュタグは
- RTK Query APIはUI非依存でReact外でも利用可能
- エンドポイントオブジェクトにはリクエスト開始/結果セレクター生成/アクションオブジェクトマッチング機能が含まれる
- レスポンスデータを必要に応じて変換可能
transformResponseコールバックでキャッシュ前のデータ変換を定義可能selectFromResultオプションでデータ抽出/変換可能- コンポーネントは
useMemoで値全体を読み取り変換可能
- ユーザーエクスペリエンス向上のための高度なキャッシュ操作オプション
onQueryStartedライフサイクルで楽観的更新を実装(リクエスト完了前に即時キャッシュ更新)onCacheEntryAddedライフサイクルでストリーミング更新を実装(サーバープッシュ接続に基づく継続的キャッシュ更新)- RTKQエンドポイントの
matchFulfilledマッチャーで追加ロジックを実行可能(スライス状態の更新など)
次のステップ
おめでとうございます、Redux Essentialsチュートリアルを完了しました! Redux ToolkitとReact-Reduxの基本概念、Reduxロジックの記述と構成方法、Reactとの連携によるReduxデータフロー、configureStoreやcreateSliceといったAPIの使用方法を確実に理解できたはずです。RTK Queryによるデータ取得とキャッシュ活用の効率化方法も習得しました。
RTK Queryの詳細な使用方法については、RTK Query使用ガイドとAPIリファレンスを参照してください。
このチュートリアルでこれまでに学んだ概念は、ReactとReduxを使用して独自のアプリケーションを構築し始めるのに十分なはずです。これらの概念を実践で固め、実際にどのように機能するかを確認するために、自身でプロジェクトに取り組む絶好のタイミングです。どのようなプロジェクトを構築すべきかわからない場合は、アプリプロジェクトアイデアのリストを参考にインスピレーションを得てください。
Redux Essentialsチュートリアルは「Reduxの正しい使い方」に焦点を当てており、「どのように動作するか」や「なぜこのような動作をするのか」については扱っていません。特にRedux Toolkitは高レベルの抽象化とユーティリティの集合体であり、RTKの抽象化が実際に何をしているのか理解することは有益です。「Redux Fundamentals」チュートリアルを読むことで、Reduxコードを「手動で」書く方法と、Reduxロジックを記述するデフォルトの方法としてRedux Toolkitを推奨する理由を理解するのに役立ちます。
Reduxの使用セクションには、リデューサーの構造化方法など、多くの重要な概念に関する情報が掲載されており、スタイルガイドには推奨パターンとベストプラクティスに関する重要な情報が記載されています。
Reduxが_なぜ_存在するのか、どのような問題を解決しようとしているのか、どのように使用されることを意図しているのかについてさらに知りたい場合は、ReduxメンテナーのMark EriksonによるThe Tao of Redux, Part 1: Implementation and IntentとThe Tao of Redux, Part 2: Practice and Philosophyの記事を参照してください。
Reduxに関する質問のサポートが必要な場合は、DiscordのReactifluxサーバー内の#reduxチャンネルに参加してください。
このチュートリアルをお読みいただきありがとうございます。Reduxでのアプリケーション構築をお楽しみください!