Reduxの基本、パート7: RTK Queryの基礎
このページは PageTurner AI で翻訳されました(ベータ版)。プロジェクト公式の承認はありません。 エラーを見つけましたか? 問題を報告 →
- RTK QueryがReduxアプリのデータ取得をどのように簡素化するか
- RTK Queryの設定方法
- 基本的なデータ取得と更新リクエストにRTK Queryを使用する方法
- Redux Toolkitの使用パターンを理解するため、本チュートリアルの前セクションを完了していること
動画コースを希望される場合は、RTK Query開発者Lenz Weber-Tronicによる無料のEgghead動画コースをご視聴いただくか、以下の最初のレッスンを直接ご覧ください:
はじめに
パート5: 非同期ロジックとデータ取得およびパート6: パフォーマンスと正規化では、Reduxを使ったデータ取得とキャッシュの標準パターンを学びました。これには非同期サンクによるデータ取得、結果を含むアクションのディスパッチ、ストア内でのリクエストローディング状態の管理、個別アイテムのID検索や更新を容易にするキャッシュデータの正規化が含まれます。
このセクションでは、Reduxアプリケーション向けに設計されたデータ取得・キャッシュソリューションであるRTK Queryの使用方法を学び、データ取得プロセスとコンポーネントでの利用がどのように簡素化されるかを確認します。
RTK Queryの概要
RTK Queryは強力なデータ取得・キャッシュツールです。Webアプリケーションにおける一般的なデータ読み込みケースを簡素化するよう設計されており、データ取得&キャッシュロジックを手動で実装する必要性を排除します。
RTK QueryはRedux Toolkitパッケージに含まれており、その機能はRedux Toolkitの他のAPI上に構築されています。Reduxアプリでのデータ取得にはRTK Queryをデフォルトアプローチとして推奨します。
開発背景
Webアプリケーションは通常、データ表示のためにサーバーからデータ取得する必要があります。さらにデータ更新を行い、更新内容をサーバーへ送信し、クライアントのキャッシュデータをサーバーと同期させる必要もあります。現代アプリケーションで必要となる次の挙動により、この処理はさらに複雑になります:
-
UIスピナー表示のためのローディング状態追跡
-
同一データに対する重複リクエストの回避
-
UIの体感速度向上のための楽観的更新
-
ユーザー操作に伴うキャッシュライフタイム管理
Redux Toolkitを使用してこれらの挙動を実装する方法は既に学びました。
しかし従来のReduxには、これらのユースケースを_完全に_解決する組み込み機能はありませんでした。createAsyncThunkとcreateSliceを併用しても、リクエスト作成やローディング状態管理には相当な手作業が必要です。非同期サンクの作成、実際のリクエスト実行、レスポンスからの関連フィールド抽出、ローディング状態フィールドの追加、pending/fulfilled/rejectedケースを処理するextraReducersハンドラーの追加、そして適切な状態更新の記述が必要です。
時が経つにつれ、Reactコミュニティは**「データ取得とキャッシング」が「状態管理」とは根本的に異なる関心事**であると認識するようになりました。Reduxのような状態管理ライブラリでデータをキャッシュすることは可能ですが、ユースケースが大きく異なるため、データ取得に特化したツールを使用する価値があります。
サーバー状態の課題
React Queryの「Motivation」ドキュメントページの優れた説明を引用する価値があります:
従来の状態管理ライブラリのほとんどはクライアント状態の扱いに優れていますが、非同期状態やサーバー状態の扱いにはあまり適していません。これはサーバー状態が根本的に異なる性質を持つためです。まず、サーバー状態は:
- あなたが管理/所有していない遠隔地に永続化される
- 取得や更新に非同期APIを必要とする
- 共有所有権を意味し、他の人が知らぬ間に変更できる
- 注意しないとアプリケーション内で「陳腐化」する可能性がある
アプリケーション内のサーバー状態の性質を理解すると、さらに多くの課題が浮上します:
- キャッシング(おそらくプログラミングで最も難しい作業)
- 同じデータへの複数リクエストを単一リクエストに重複排除
- バックグラウンドで「陳腐化」データを更新
- データが「陳腐化」したタイミングの把握
- データ更新を可能な限り迅速に反映
- ページネーションや遅延読み込みなどのパフォーマンス最適化
- サーバー状態のメモリ管理とガベージコレクション
- 構造的共有によるクエリ結果のメモ化
RTK Queryの違い
RTK QueryはApollo Client、React Query、Urql、SWRなどのデータ取得ソリューションの先駆者からインスピレーションを得つつ、API設計に独自のアプローチを追加しています:
-
データ取得とキャッシングロジックはRedux Toolkitの
createSliceおよびcreateAsyncThunkAPI上に構築 -
Redux ToolkitはUI非依存のため、RTK Queryの機能はReactだけでなくAngular、Vue、Vanilla JSなど任意のUI層で使用可能
-
引数からクエリパラメータを生成する方法やキャッシング用のレスポンス変換方法を含め、APIエンドポイントを事前定義
-
データ取得プロセス全体をカプセル化するReactフックを自動生成可能(コンポーネントに
dataやisFetchingを提供し、マウント/アンマウント時のキャッシュ寿命を管理) -
WebSocketメッセージ経由の初期データ取得後キャッシュ更新など、「キャッシュエントリライフサイクル」オプションを提供
-
OpenAPIスキーマからRTK Query API定義を生成するコードジェネレーターを提供
-
完全にTypeScriptで記述され、優れたTS開発体験を提供
提供機能
API
RTK QueryはコアのRedux Toolkitパッケージに含まれ、以下のエントリポイントから利用可能です:
// UI-agnostic entry point with the core logic
import { createApi } from '@reduxjs/toolkit/query'
// React-specific entry point that automatically generates
// hooks corresponding to the defined endpoints
import { createApi } from '@reduxjs/toolkit/query/react'
RTK Queryは主に2つのAPIで構成されます:
createApi(): RTK Queryの機能の中核です。これにより、一連のエンドポイントからデータを取得する方法を記述するエンドポイントのセットを定義できます。これにはデータの取得方法と変換方法の設定が含まれます。ほとんどの場合、アプリごとに1回使用する必要があり、経験則として「1つのベースURLごとに1つのAPIスライス」とします。
fetchBaseQuery():HTTPリクエストを簡素化するfetchのラッパー。RTK Queryは任意の非同期リクエスト結果をキャッシュ可能ですが、HTTPリクエストが最も一般的なため、fetchBaseQueryが標準でHTTPサポートを提供
バンドルサイズ
RTK Queryはアプリのバンドルサイズに固定のワンタイム容量を追加します。RTK QueryはRedux ToolkitとReact-Redux上に構築されているため、追加サイズは既にそれらを使用しているかどうかによって異なります。推定min+gzipバンドルサイズは以下の通りです:
-
既にRTKを使用している場合:RTK Queryで約9kb、フックで約2kb
-
まだRTKを使用していない場合:
- Reactなし:RTK+依存関係+RTK Queryで17kB
- Reactあり:19kB + React-Redux(peer dependency)
追加のエンドポイント定義は、通常わずか数バイトのendpoints定義内の実際のコードに基づいてのみサイズを増加させます。
RTK Queryの機能は追加バンドルサイズを迅速に相殺し、手書きのデータ取得ロジックの排除により、ほとんどの実用的アプリケーションではサイズの純改善となります。
RTK Queryキャッシュの考え方
Reduxは常に予測可能性と明示的な動作を重視してきました。Reduxには「魔法」はありません。すべてのReduxロジックはアクションのディスパッチとリデューサーによる状態更新という同じ基本パターンに従うため、アプリケーションで何が起こっているかを理解できるはずです。これは時にはより多くのコードを書く必要があることを意味しますが、トレードオフとしてデータフローと動作が非常に明確になります。
Redux ToolkitコアAPIはReduxアプリの基本データフローを変更しません。依然としてアクションをディスパッチしリデューサーを書きますが、手動で全ロジックを書くよりも少ないコードで済みます。RTK Queryも同様です。これは追加の抽象化レイヤーですが、内部的には非同期リクエスト管理のために既に見てきたのと同じ手順を実行しています - 非同期リクエスト実行にthunkを使用し、結果と共にアクションをディスパッチし、リデューサーでアクションを処理してデータをキャッシュします。
ただしRTK Queryを使用する際には、考え方の転換が発生します。もはや「状態管理」自体を考えるのではなく、「キャッシュデータの管理」について考えます。リデューサーを自ら書こうとする代わりに、**「このデータはどこから来るか?」「この更新はどう送信すべきか?」「キャッシュデータはいつ再取得すべきか?」「キャッシュデータはどう更新すべきか?」**の定義に焦点を当てます。データの取得・保存・取得方法は、もはや気にする必要のない実装詳細になります。
この考え方の転換がどう適用されるか、続ける中で見ていきましょう。
RTK Queryの設定
サンプルアプリケーションは既に動作しますが、すべての非同期ロジックをRTK Queryに移行する時が来ました。進めながら、RTK Queryの主要機能の使用方法と、既存のcreateAsyncThunkやcreateSliceの使用をRTK Query APIに移行する方法を見ていきます。
APIスライスの定義
以前は、投稿・ユーザー・通知といった各データタイプごとに個別の「スライス」を定義していました。各スライスは独自のリデューサーを持ち、独自のアクションとthunkを定義し、そのデータタイプのエントリを個別にキャッシュしていました。
RTK Queryでは、キャッシュデータ管理ロジックはアプリケーションごとに単一の「APIスライス」に集約されます。アプリごとに単一のReduxストアを持つのと同様に、今や_すべて_のキャッシュデータに対して単一のスライスを持ちます。
新しいapiSlice.tsファイルの定義から始めます。これは既に書かれた他の「フィーチャー」に特化しないため、新規にfeatures/api/フォルダを追加し、そこにapiSlice.tsを配置します。APIスライスファイルを記述し、その後内部のコードを分解してその動作を確認しましょう:
// Import the RTK Query methods from the React-specific entry point
import { createApi, fetchBaseQuery } from '@reduxjs/toolkit/query/react'
// Use the `Post` type we've already defined in `postsSlice`,
// and then re-export it for ease of use
import type { Post } from '@/features/posts/postsSlice'
export type { Post }
// Define our single API slice object
export const apiSlice = createApi({
// The cache reducer expects to be added at `state.api` (already default - this is optional)
reducerPath: 'api',
// All of our requests will have URLs starting with '/fakeApi'
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
// The "endpoints" represent operations and requests for this server
endpoints: builder => ({
// The `getPosts` endpoint is a "query" operation that returns data.
// The return value is a `Post[]` array, and it takes no arguments.
getPosts: builder.query<Post[], void>({
// The URL for the request is '/fakeApi/posts'
query: () => '/posts'
})
})
})
// Export the auto-generated hook for the `getPosts` query endpoint
export const { useGetPostsQuery } = apiSlice
RTK Queryの機能はcreateApiという単一のメソッドに基づいています。これまで見てきたRedux ToolkitのAPIはすべてUIに依存せず、あらゆるUI層で使用可能です。RTK Queryのコアロジックも同様です。ただしRTK QueryにはReact専用バージョンのcreateApiも含まれており、RTKとReactを併用する場合にはこのReact統合機能を活用する必要があります。そのため'@reduxjs/toolkit/query/react'から具体的にインポートします。
アプリケーション内でcreateApiを呼び出すのは1回だけにする必要があります。この単一のAPIスライスに、同じベースURLと通信する全エンドポイント定義を含めるべきです。例えば/api/postsと/api/usersのエンドポイントはどちらも同じサーバーからデータを取得するため、同一のAPIスライスに属します。複数のサーバーからデータを取得する場合は、各エンドポイントで完全なURLを指定するか、やむを得ない場合に限りサーバーごとに別々のAPIスライスを作成します。
エンドポイントは通常createApi呼び出し内で直接定義します。複数ファイルに分割したい場合は、ドキュメントのPart 8「エンドポイントの注入」セクションを参照してください!
APIスライスのパラメーター
createApiを呼び出す際に必須となるパラメーターが2つあります:
-
baseQuery: サーバーからデータを取得する方法を知っている関数。RTK Queryには標準fetch()関数をラップしたfetchBaseQueryが含まれており、HTTPリクエストとレスポンスの一般的な処理を担当します。fetchBaseQueryインスタンスを作成する際、全リクエストのベースURLを渡せるほか、リクエストヘッダーの変更などの動作をオーバーライドできます。カスタムベースクエリの作成により、エラー処理や認証などの動作をカスタマイズ可能です。 -
endpoints: このサーバーと対話するために定義した操作のセット。エンドポイントにはデータをキャッシュ用に返すクエリと、サーバーへ更新を送信するミューテーションがあります。エンドポイントはbuilderパラメーターを受け取るコールバック関数で定義され、builder.query()とbuilder.mutation()で作成したエンドポイント定義を含むオブジェクトを返します。
createApiはreducerPathフィールドも受け付け、生成されたレデューサーが配置されるトップレベルの状態スライスを定義します。postsSliceのような他のスライスでは、state.postsを更新することが保証されていません(レデューサーをルート状態の任意の場所、例えば someOtherField: postsReducer のようにアタッチ可能です)。ここではcreateApiが、キャッシュレデューサーをストアに追加する際のキャッシュ状態の場所を明示するよう求めます。reducerPathオプションを指定しない場合、デフォルトで'api'となり、RTKQのキャッシュデータはすべてstate.api下に保存されます。
レデューサーをストアに追加し忘れた場合やreducerPathで指定したキーと異なる場所にアタッチした場合、RTKQはエラーをログ出力して修正が必要であることを通知します。
エンドポイントの定義
全リクエストのURLの最初の部分は、fetchBaseQuery定義内で'/fakeApi'と指定されています。
最初のステップとして、フェイクAPIサーバーから投稿の全リストを返すエンドポイントを追加します。getPostsというエンドポイントを作成し、builder.query()を使用してクエリエンドポイントとして定義します。このメソッドはリクエストの作成方法やレスポンスの処理方法を設定する多くのオプションを受け付けます。現時点では、queryオプションにURL文字列を返すコールバック() => '/posts'を指定するだけで十分です。
デフォルトでは、クエリエンドポイントは GET HTTP リクエストを使用しますが、URL文字列の代わりに {url: '/posts', method: 'POST', body: newPost} のようなオブジェクトを返すことで上書きできます。この方法でリクエストのヘッダー設定など、他のオプションも定義可能です。
TypeScriptを使用する場合、builder.query() と builder.mutation() エンドポイント定義関数は2つのジェネリック引数 <ReturnType, ArgumentType> を受け取ります。例えば、名前でポケモンを取得するエンドポイントは getPokemonByName: builder.query<Pokemon, string>() のようになります。引数を取らないエンドポイントの場合は void 型を使用します(例:getAllPokemon: builder.query<Pokemon[], void>())。
APIスライスとフックのエクスポート
これまでのcreateSlice関数では、他のファイルで必要なのはスライス関数の一部であるアクションクリエーターとスライスリデューサーのみだったため、これらだけをエクスポートすれば十分でした。一方RTK Queryでは、複数の有用なフィールドが含まれているため、通常は「APIスライス」オブジェクト全体をエクスポートします。
最後に、このファイルの最終行に注目してください。useGetPostsQuery という値はどこから来ているのでしょうか?
RTK QueryのReact統合機能は、定義したすべてのエンドポイントに対してReactフックを自動生成します! これらのフックは、コンポーネントのマウント時にリクエストをトリガーし、リクエスト処理中やデータ取得時にコンポーネントを再レンダリングするプロセスをカプセル化します。生成されたフックはAPIスライスファイルからエクスポートし、Reactコンポーネントで使用できます。
フックは標準的な命名規則に基づいて自動命名されます:
-
use(すべてのReactフックの標準プレフィックス) -
エンドポイント名(先頭大文字)
-
エンドポイントタイプ(
QueryまたはMutation)
今回のケースでは、エンドポイント名が getPosts でクエリタイプなので、生成されるフック名は useGetPostsQuery となります。
ストアの設定
APIスライスをReduxストアに接続する必要があります。既存の store.ts ファイルを修正し、APIスライスのキャッシュリデューサーを状態に追加します。さらに、APIスライスが生成するカスタムミドルウェアもストアに追加する必要があります。このミドルウェアはキャッシュのライフタイムと期限切れ管理を行うため、必須で追加しなければなりません。
import { configureStore } from '@reduxjs/toolkit'
import { apiSlice } from '@/features/api/apiSlice'
import authReducer from '@/features/auth/authSlice'
import postsReducer from '@/features/posts/postsSlice'
import usersReducer from '@/features/users/usersSlice'
import notificationsReducer from '@/features/notifications/notificationsSlice'
import { listenerMiddleware } from './listenerMiddleware'
export const store = configureStore({
// Pass in the root reducer setup as the `reducer` argument
reducer: {
auth: authReducer,
posts: postsReducer,
users: usersReducer,
notifications: notificationsReducer,
[apiSlice.reducerPath]: apiSlice.reducer
},
middleware: getDefaultMiddleware =>
getDefaultMiddleware()
.prepend(listenerMiddleware.middleware)
.concat(apiSlice.middleware)
})
reducer パラメーターで apiSlice.reducerPath フィールドを計算済みキーとして再利用することで、キャッシュリデューサーが適切な場所に追加されることを保証できます。
リスナーミドルウェアの追加時と同様に、redux-thunk などの既存の標準ミドルウェアを維持する必要があります。APIスライスのミドルウェアは通常これらより後に配置します。getDefaultMiddleware() を呼び出してリスナーミドルウェアを先頭に置いているので、末尾に追加するには .concat(apiSlice.middleware) を呼び出します。
クエリを使用した投稿の表示
コンポーネントでのクエリフックの使用
APIスライスを定義してストアに追加したので、生成された useGetPostsQuery フックを <PostsList> コンポーネントにインポートして使用できます。
現在、<PostsList> は useSelector、useDispatch、useEffect をインポートし、ストアから投稿データとローディング状態を読み取り、マウント時に fetchPosts() サンクをディスパッチしてデータ取得をトリガーしています。useGetPostsQueryHook はこれらすべてを置き換えます!
このフックを使用した場合の <PostsList> の実装を見てみましょう:
import React from 'react'
import { Link } from 'react-router-dom'
import { Spinner } from '@/components/Spinner'
import { TimeAgo } from '@/components/TimeAgo'
import { useGetPostsQuery, Post } from '@/features/api/apiSlice'
import { PostAuthor } from './PostAuthor'
import { ReactionButtons } from './ReactionButtons'
// Go back to passing a `post` object as a prop
interface PostExcerptProps {
post: Post
}
function PostExcerpt({ post }: PostExcerptProps) {
return (
<article className="post-excerpt" key={post.id}>
<h3>
<Link to={`/posts/${post.id}`}>{post.title}</Link>
</h3>
<div>
<PostAuthor userId={post.user} />
<TimeAgo timestamp={post.date} />
</div>
<p className="post-content">{post.content.substring(0, 100)}</p>
<ReactionButtons post={post} />
</article>
)
}
export const PostsList = () => {
// Calling the `useGetPostsQuery()` hook automatically fetches data!
const {
data: posts = [],
isLoading,
isSuccess,
isError,
error
} = useGetPostsQuery()
let content: React.ReactNode
// Show loading states based on the hook status flags
if (isLoading) {
content = <Spinner text="Loading..." />
} else if (isSuccess) {
content = posts.map(post => <PostExcerpt key={post.id} post={post} />)
} else if (isError) {
content = <div>{error.toString()}</div>
}
return (
<section className="posts-list">
<h2>Posts</h2>
{content}
</section>
)
}
概念的には <PostsList> は以前と同じ処理を行っていますが、複数の useSelector 呼び出しと useEffect ディスパッチを、単一の useGetPostsQuery() 呼び出しで置き換えることができました。
(注: この時点では、既存の state.posts スライスを参照しているコードと、RTK Queryからデータを取得する新しいコードとの間に不一致が生じます。これは予期された動作であり、順次修正していきます。)
以前は、ストアから投稿IDのリストを選択し、各 <PostExcerpt> コンポーネントに投稿IDを渡し、個々の Post オブジェクトをストアから個別に選択していました。今回、posts 配列にはすべての投稿オブジェクトが含まれているため、投稿オブジェクト自体をpropsとして渡す方式に戻しました。
キャッシュされたデータにアクセスする際は、通常クエリフックを使用してください。取得したデータにアクセスするための独自の useSelector 呼び出しや、データ取得をトリガーする useEffect 呼び出しを記述すべきではありません!
クエリフックの結果オブジェクト
生成された各クエリフックは、以下のフィールドを含む「結果」オブジェクトを返します:
-
data: サーバーからの最新の成功したキャッシュエントリの実際の応答内容。応答受信まではundefinedになります。 -
currentData: 現在のクエリ引数に対する応答内容。クエリ引数が変更され、既存のキャッシュエントリがないためにリクエストが開始されるとundefinedに切り替わる可能性があります。 -
isLoading: データがまだ存在しないため、このフックが現在サーバーへの最初のリクエストを行っているかどうかを示すブール値(異なるデータをリクエストするためにパラメータが変更された場合、isLoadingはfalseのままです) -
isFetching: フックが現在サーバーへのあらゆるリクエストを行っているかどうかを示すブール値 -
isSuccess: フックがリクエストに成功し、キャッシュデータが利用可能であることを示すブール値(dataが定義されているはずです) -
isError: 最後のリクエストでエラーが発生したかどうかを示すブール値 -
error: シリアライズされたエラーオブジェクト
結果オブジェクトからフィールドを分割代入し、data を posts のようなより具体的な変数名にリネームするのが一般的です。その後、ステータスブール値と data/error フィールドを使用して目的のUIをレンダリングできます。ただし、古いバージョンのTypeScriptを使用している場合、条件チェックで result.isSuccess のように元のオブジェクトを参照する必要があるかもしれません(これによりTSが data が有効であると正しく推論できます)。
ローディング状態フィールド
isLoading と isFetching は異なる動作をする別々のフラグです。UIでローディング状態を表示するタイミングと方法に基づいて、どちらを使用するか決定できます。例えば、ページを初めてロードする際にスケルトンを表示したい場合は isLoading をチェックし、ユーザーが異なる項目を選択するたびにリクエストが発生した際にスピナーを表示したり既存の結果をグレーアウトしたい場合は isFetching を選択できます。
同様に、data と currentData は異なるタイミングで変化します。ほとんどの場合 data の値を使用すべきですが、currentData はローディング動作をより細かく制御できます。例えば、再フェッチ状態を表現するために半透明でUIにデータを表示したい場合、data と isFetching を組み合わせて実現できます(新しいリクエストが完了するまで data は同じままです)。ただし、現在の引数に対応する値のみを表示したい場合(新しいリクエストが完了するまでUIをクリアしたい場合など)は、代わりに currentData を使用できます。
投稿のソート
残念ながら、投稿が順不同で表示されています。以前は createEntityAdapter のソートオプションでリデューサレベルで日付順にソートしていました。APIスライスはサーバーから返された配列をそのままキャッシュするため、特定のソートは行われません(サーバーが返した順序がそのまま保持されます)。
現時点では、これを処理する方法がいくつか考えられます。ここでは、<PostsList>内でソートを行う方法を採用し、他の選択肢とそのトレードオフについては後で説明します。
posts.sort()を直接呼び出すことはできません。なぜならArray.sort()は既存の配列を変更するため、まずコピーを作成する必要があるからです。また、再レンダリングのたびに再ソートしないようにするため、useMemo()フック内でソート処理を行います。さらに、ソート対象の配列が常に存在するよう、postsがundefinedの場合に備えてデフォルトの空配列を設定します。
// omit setup
export const PostsList = () => {
const {
data: posts = [],
isLoading,
isSuccess,
isError,
error
} = useGetPostsQuery()
const sortedPosts = useMemo(() => {
const sortedPosts = posts.slice()
// Sort posts in descending chronological order
sortedPosts.sort((a, b) => b.date.localeCompare(a.date))
return sortedPosts
}, [posts])
let content
if (isLoading) {
content = <Spinner text="Loading..." />
} else if (isSuccess) {
content = sortedPosts.map(post => <PostExcerpt key={post.id} post={post} />)
} else if (isError) {
content = <div>{error.toString()}</div>
}
// omit rendering
}
個別投稿の表示
<PostsList>を更新して_すべて_の投稿リストを取得し、リスト内に各Postの一部を表示しています。しかし、いずれかの投稿の「View Post」をクリックすると、従来のstate.postsスライスから投稿を見つけられず、<SinglePostPage>コンポーネントが「Post not found!」エラーを表示します。<SinglePostPage>もRTK Queryを使用するように更新する必要があります。
これにはいくつかの方法があります。1つは<SinglePostPage>が同じuseGetPostsQuery()フックを呼び出して投稿の_全件_配列を取得し、表示する必要がある1つのPostオブジェクトだけを見つける方法です。クエリフックにはselectFromResultオプションもあり、フック内で同じ検索を早期に行えます(これは後ほど実際に見ていきます)。
代わりに、サーバーからIDに基づいて単一の投稿を取得できる別のエンドポイント定義を追加してみます。これは若干冗長ですが、RTK Queryが引数に基づいてクエリリクエストをカスタマイズする方法を理解するのに役立ちます。
単一投稿クエリエンドポイントの追加
apiSlice.tsに、getPost(今回は's'なし)という別のクエリエンドポイント定義を追加します:
export const apiSlice = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
endpoints: builder => ({
getPosts: builder.query<Post[], void>({
query: () => '/posts'
}),
getPost: builder.query<Post, string>({
query: postId => `/posts/${postId}`
})
})
})
export const { useGetPostsQuery, useGetPostQuery } = apiSlice
getPostエンドポイントは既存のgetPostsと似ていますが、queryパラメータが異なります。ここでは、queryはpostIdという引数を受け取り、そのpostIdを使用してサーバーURLを構築します。これにより、特定のPostオブジェクトだけをサーバーにリクエストできます。
これにより新しいuseGetPostQueryフックも生成されるため、こちらもエクスポートします。
クエリ引数とキャッシュキー
現在<SinglePostPage>はIDに基づいてstate.postsから1つのPostエントリを読み取っています。これを新しいuseGetPostQueryフックを呼び出すように更新し、メインリストと同様のローディング状態を使用します。
// omit some imports
import { useGetPostQuery } from '@/features/api/apiSlice'
import { selectCurrentUsername } from '@/features/auth/authSlice'
export const SinglePostPage = () => {
const { postId } = useParams()
const currentUsername = useAppSelector(selectCurrentUsername)
const { data: post, isFetching, isSuccess } = useGetPostQuery(postId!)
let content: React.ReactNode
const canEdit = currentUsername === post?.user
if (isFetching) {
content = <Spinner text="Loading..." />
} else if (isSuccess) {
content = (
<article className="post">
<h2>{post.title}</h2>
<div>
<PostAuthor userId={post.user} />
<TimeAgo timestamp={post.date} />
</div>
<p className="post-content">{post.content}</p>
<ReactionButtons post={post} />
{canEdit && (
<Link to={`/editPost/${post.id}`} className="button">
Edit Post
</Link>
)}
</article>
)
}
return <section>{content}</section>
}
ルーターのマッチから取得したpostIdを引数としてuseGetPostQueryに渡している点に注目してください。クエリフックはこれを使用してリクエストURLを構築し、この特定のPostオブジェクトを取得します。
では、このデータはどのようにキャッシュされているのでしょうか?投稿エントリの1つで「View Post」をクリックし、この時点でのReduxストアの中身を見てみましょう。
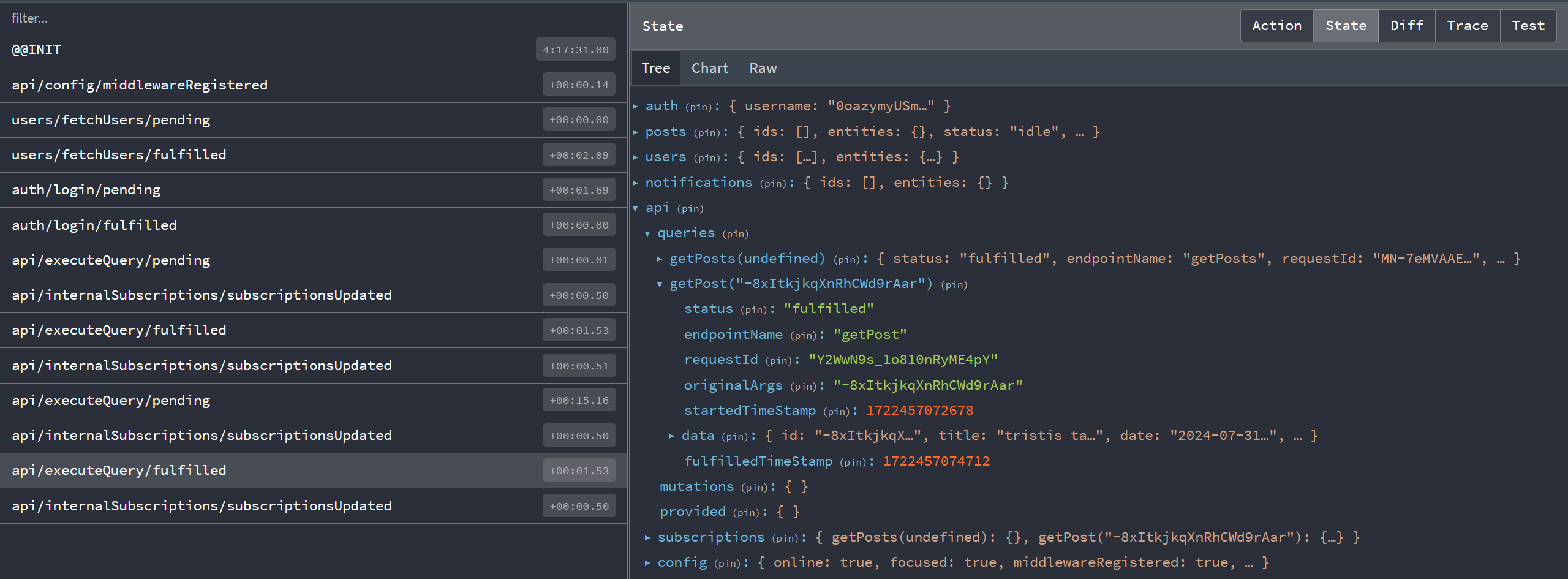
ストア設定から予想されるように、トップレベルにstate.apiスライスがあることがわかります。その中にはqueriesというセクションがあり、現在2つのアイテムが含まれています。キーgetPosts(undefined)は、getPostsエンドポイントで行ったリクエストのメタデータとレスポンス内容を表しています。同様に、キーgetPost('abcd1234')はこの特定の投稿に対して行ったリクエスト用です。
RTK Queryは各エンドポイント+引数の組み合わせに対して「キャッシュキー」を作成し、各キャッシュキーの結果をReduxストアに個別に保存します。つまり、同じクエリフックを複数回使用し、異なるクエリパラメータを渡しても、各結果がReduxストアに個別にキャッシュされるということです。
複数のコンポーネントで同じデータが必要な場合、各コンポーネントで同じ引数を使って同じクエリフックを呼び出してください!例えば、3つの異なるコンポーネントで useGetPostQuery('123') を呼び出しても、RTK Query はデータを1回だけ取得し、各コンポーネントは必要に応じて再レンダリングされます。
重要な点として、クエリパラメータは単一の値でなければなりません!複数のパラメータを渡す必要がある場合は、createAsyncThunk と同様に複数フィールドを持つオブジェクトを渡す必要があります。RTK Query はフィールドの「浅い比較(shallow stable comparison)」を行い、いずれかの値が変更された場合にデータを再取得します。
左側のリストにあるアクション名(api/executeQuery/fulfilled など)が汎用的で具体的な内容が分かりにくい点に注目してください(posts/fetchPosts/fulfilled のような具体的な名前ではありません)。これは抽象化レイヤーを追加した場合のトレードオフです。個々のアクションには action.meta.arg.endpointName に具体的なエンドポイント名が含まれますが、アクション履歴リストでは確認しにくくなっています。
Redux DevToolsには「RTK Query」タブがあり、生のRedux状態構造ではなくキャッシュエントリに焦点を当てた形式でRTK Queryデータを分かりやすく表示します。これには各エンドポイントとキャッシュ結果の情報、クエリ時間の統計などが含まれます:
以下のライブデモでもRTK Query開発者ツールを確認できます:
ミューテーションを使った投稿の作成
これまで「クエリ」エンドポイントを定義してサーバーからデータを取得する方法を見てきましたが、サーバーへの更新送信はどうでしょうか?
RTK Queryでは、サーバーのデータを更新するミューテーションエンドポイントを定義できます。新しい投稿を追加できるミューテーションを追加しましょう。
新規投稿ミューテーションエンドポイントの追加
ミューテーションエンドポイントの追加はクエリエンドポイントの追加と非常に似ています。主な違いは、builder.query() の代わりに builder.mutation() を使ってエンドポイントを定義することです。また、HTTPメソッドを 'POST' リクエストに変更し、リクエストの本文(body)を提供する必要もあります。
既存の NewPost TS型を postsSlice.ts からエクスポートし、このミューテーションの引数型として使用します。これはコンポーネントが渡す必要がある値だからです。
import { createApi, fetchBaseQuery } from '@reduxjs/toolkit/query/react'
import type { Post, NewPost } from '@/features/posts/postsSlice'
export type { Post }
export const apiSlice = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
endpoints: builder => ({
getPosts: builder.query<Post[], void>({
query: () => '/posts'
}),
getPost: builder.query<Post, string>({
query: postId => `/posts/${postId}`
}),
addNewPost: builder.mutation<Post, NewPost>({
query: initialPost => ({
// The HTTP URL will be '/fakeApi/posts'
url: '/posts',
// This is an HTTP POST request, sending an update
method: 'POST',
// Include the entire post object as the body of the request
body: initialPost
})
})
})
})
export const {
useGetPostsQuery,
useGetPostQuery,
useAddNewPostMutation
} = apiSlice
クエリエンドポイントと同様に、TS型を指定します:ミューテーションは完全な Post を返し、引数として部分的な NewPost 値を受け取ります。
ここでは query オプションが {url, method, body} を含むオブジェクトを返します。これにより、HTTP POST メソッドリクエストであることと、body の内容を指定できます。fetchBaseQuery を使ってリクエストを行うため、body フィールドは自動的にJSONシリアライズされます(この例では「post」という単語が明らかに多く出現していますが :) )
クエリエンドポイントと同様に、APIスライスはミューテーションエンドポイント用のReactフックを自動生成します。今回は useAddNewPostMutation です。
コンポーネントでのミューテーションフックの使用
既存の <AddPostForm> は「Save Post」ボタンがクリックされるたびに投稿を追加するため非同期thunkをディスパッチしています。そのためには useDispatch と addNewPost thunkをインポートする必要がありました。ミューテーションフックはこれら両方を置き換え、使用パターンは基本的に同じです:
import React from 'react'
import { useAppSelector } from '@/app/hooks'
import { useAddNewPostMutation } from '@/features/api/apiSlice'
import { selectCurrentUsername } from '@/features/auth/authSlice'
// omit field types
export const AddPostForm = () => {
const userId = useAppSelector(selectCurrentUsername)!
const [addNewPost, { isLoading }] = useAddNewPostMutation()
const handleSubmit = async (e: React.FormEvent<AddPostFormElements>) => {
// Prevent server submission
e.preventDefault()
const { elements } = e.currentTarget
const title = elements.postTitle.value
const content = elements.postContent.value
const form = e.currentTarget
try {
await addNewPost({ title, content, user: userId }).unwrap()
form.reset()
} catch (err) {
console.error('Failed to save the post: ', err)
}
}
return (
<section>
<h2>Add a New Post</h2>
<form onSubmit={handleSubmit}>
<label htmlFor="postTitle">Post Title:</label>
<input
type="text"
id="postTitle"
name="postTitle"
defaultValue=""
required
/>
<label htmlFor="postContent">Content:</label>
<textarea
id="postContent"
name="postContent"
defaultValue=""
required
/>
<button disabled={isLoading}>Save Post</button>
</form>
</section>
)
}
ミューテーションフックは2つの値を持つ配列を返します:
-
最初の値は「トリガー関数」です。呼び出されると、提供された引数を使ってサーバーへリクエストを行います。これは実際には自身を即座にディスパッチするようラップされたthunkです。
-
2番目の値は、進行中のリクエストに関するメタデータを含むオブジェクトです(存在する場合)。これにはリクエストが進行中かどうかを示す
isLoadingフラグが含まれます。
既存の非同期処理ディスパッチとコンポーネントのローディング状態を、useAddNewPostMutationフックから取得したトリガー関数とisLoadingフラグで置き換えられます。コンポーネントのその他の部分は変更ありません。
前回の非同期処理ディスパッチと同様に、addNewPostを初期ポストオブジェクトと共に呼び出します。これにより.unwrap()メソッドを持つ特別なPromiseが返されます。エラー処理には標準のtry/catchブロックを使用し、await addNewPost().unwrap()で待機できます(これはcreateAsyncThunkの処理と同じです。内部的にRTK QueryはcreateAsyncThunkを使用しているためです)。
キャッシュデータの更新
「Save Post」をクリックすると、ブラウザの開発者ツールでネットワークタブを確認しHTTP POSTリクエストが成功したことを確認できます。しかし、<PostsList>に戻っても新しい投稿は表示されません。Reduxストアの状態は変更されておらず、メモリ内のキャッシュデータも同じままです。
RTK Queryに投稿リストのキャッシュ更新を指示し、追加した新しい投稿を表示できるようにする必要があります。
手動での投稿再取得
最初の方法は、RTK Queryに特定エンドポイントのデータ再取得を強制する手動更新です。実際のアプリケーションでは推奨されませんが、中間ステップとして試してみましょう。
クエリフックの結果オブジェクトにはrefetch関数が含まれており、データ再取得を強制できます。一時的に<PostsList>に「投稿を再取得」ボタンを追加し、新しい投稿後にクリックします:
export const PostsList = () => {
const {
data: posts = [],
isLoading,
isSuccess,
isError,
error,
refetch
} = useGetPostsQuery()
// omit content
return (
<section className="posts-list">
<h2>Posts</h2>
<button onClick={refetch}>Refetch Posts</button>
{content}
</section>
)
}
これで新しい投稿を追加して完了後、「Refetch Posts」をクリックすると新しい投稿が表示されるはずです。
残念ながら、再取得が進行中であることを示すインジケーターがありません。リクエスト進行中であることを示す表示があると便利でしょう。
前述のように、クエリフックにはisLoadingフラグ(初回データ取得時にtrue)とisFetchingフラグ(データ取得リクエスト中にtrue)があります。isFetchingフラグを監視し、再取得中に投稿リスト全体をローディングスピナーで置き換えることも可能です。しかしこれは煩わしく、既に投稿データがあるのに非表示にする理由もありません。
代わりに、データが古いことを示すために既存の投稿リストを半透明にしつつ表示したままにします。リクエスト完了後、通常の表示に戻します。
import classnames from 'classnames'
import { useGetPostsQuery, Post } from '@/features/api/apiSlice'
// omit other imports and PostExcerpt
export const PostsList = () => {
const {
data: posts = [],
isLoading,
isFetching,
isSuccess,
isError,
error,
refetch
} = useGetPostsQuery()
const sortedPosts = useMemo(() => {
const sortedPosts = posts.slice()
sortedPosts.sort((a, b) => b.date.localeCompare(a.date))
return sortedPosts
}, [posts])
let content: React.ReactNode
if (isLoading) {
content = <Spinner text="Loading..." />
} else if (isSuccess) {
const renderedPosts = sortedPosts.map(post => (
<PostExcerpt key={post.id} post={post} />
))
const containerClassname = classnames('posts-container', {
disabled: isFetching
})
content = <div className={containerClassname}>{renderedPosts}</div>
} else if (isError) {
content = <div>{error.toString()}</div>
}
// omit return
}
新しい投稿後「Refetch Posts」をクリックすると、投稿リストが数秒間半透明になり、再レンダリング後に新しい投稿が先頭に追加されるのを確認できます。
キャッシュ無効化による自動更新
手動でのデータ再取得はユーザー行動によって必要な場合もありますが、通常使用には適していません。
「サーバー」には追加した投稿を含む完全な投稿リストがあることはわかっています。理想的には、ミューテーションリクエスト完了直後に投稿リストを自動更新したいところです。これによりクライアントサイドのキャッシュデータがサーバーと同期していることが保証されます。
RTK Queryでは「タグ」を使用してクエリとミューテーションの関係を定義し、自動データ更新を実現できます。「タグ」は文字列または小オブジェクトで、特定データ型に識別子を割り当て、キャッシュの一部を「無効化」します。キャッシュタグが無効化されると、そのタグが設定されたエンドポイントをRTK Queryが自動的に再取得します。
基本的なタグ使用には、APIスライスに3つの情報を追加する必要があります:
-
APIスライスオブジェクトのルートレベルに
tagTypesフィールドを追加し、'Post'などのデータ型を表す文字列タグ名の配列を宣言します -
クエリエンドポイント内の
providesTags配列:そのクエリのデータを記述する一連のタグをリスト化 -
ミューテーションエンドポイント内の
invalidatesTags配列:ミューテーション実行時に無効化される一連のタグをリスト化
APIスライスに'Post'という単一タグを追加すれば、新しい投稿を追加するたびにgetPostsエンドポイントを自動的に再取得できます:
export const apiSlice = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
tagTypes: ['Post'],
endpoints: builder => ({
getPosts: builder.query<Post[], void>({
query: () => '/posts',
providesTags: ['Post']
}),
getPost: builder.query<Post, string>({
query: postId => `/posts/${postId}`
}),
addNewPost: builder.mutation<Post, NewPost>({
query: initialPost => ({
url: '/posts',
method: 'POST',
body: initialPost
}),
invalidatesTags: ['Post']
})
})
})
これだけで完了です!「Save Post」をクリックすると、数秒後に<PostsList>コンポーネントが自動的にグレーアウトし、新しく追加された投稿が上部に表示されるよう再レンダリングされます。
文字列'Post'自体に特別な意味はないことに注意してください。'Fred'や'qwerty'など任意の文字列を使用可能です。重要なのは各フィールドで同じ文字列を使用し、RTK Queryが「このミューテーションが発生したら、同じタグ文字列がリストされているすべてのエンドポイントを無効化」と認識できるようにすることです。
学んだこと
RTK Queryを使用すると、データ取得・キャッシュ・ローディング状態の管理方法の詳細が抽象化されます。これによりアプリケーションコードが大幅に簡素化され、意図した動作の高レベルな設計に集中できるようになります。RTK Queryは既に見てきたRedux Toolkit APIと同じ基盤で実装されているため、Redux DevToolsを使って状態の変化を追跡することも可能です。
- RTK QueryはRedux Toolkitに含まれるデータ取得/キャッシュソリューション
- キャッシュされたサーバーデータの管理プロセスを抽象化し、ローディング状態管理・結果保存・リクエスト送信ロジックの実装が不要
- 非同期ThunkなどReduxと同じパターン上に構築
- RTK Queryはアプリケーションごとに単一の「APIスライス」を使用(
createApiで定義)- UI非依存版とReact専用版の
createApiを提供 - APIスライスは異なるサーバー操作のための複数「エンドポイント」を定義
- React統合時は自動生成されたReactフックを含む
- UI非依存版とReact専用版の
- クエリエンドポイント:サーバーからのデータ取得とキャッシュを可能に
- クエリフックは
data値とローディング状態フラグを返す - 手動再取得、または「タグ」を使ったキャッシュ無効化による自動再取得が可能
- クエリフックは
- ミューテーションエンドポイント:サーバー上のデータ更新を可能に
- ミューテーションフックは更新リクエスト送信用のトリガー関数とローディング状態を返す
- トリガー関数は「アンラップ」して待機可能なPromiseを返す
次のステップ
RTK Queryは堅牢なデフォルト動作を提供しますが、リクエスト管理方法のカスタマイズやキャッシュデータ操作のための豊富なオプションも備えています。パート8:RTK Query高度なパターンでは、楽観的更新などの有用な機能を実装する方法を紹介します。