Основы Redux, Часть 7: Основы RTK Query
Эта страница переведена PageTurner AI (бета). Не одобрена официально проектом. Нашли ошибку? Сообщить о проблеме →
- Как RTK Query упрощает получение данных в Redux-приложениях
- Как настроить RTK Query
- Как использовать RTK Query для базовых запросов данных и обновлений
- Прохождение предыдущих разделов этого учебника для понимания шаблонов использования Redux Toolkit
Если вы предпочитаете видеоформат, вы можете бесплатно посмотреть этот курс по RTK Query от Ленца Вебер-Троника, создателя RTK Query, на Egghead или посмотреть первый урок прямо здесь:
Введение
В Части 5: Асинхронная логика и получение данных и Части 6: Производительность и нормализация мы рассмотрели стандартные подходы к получению и кэшированию данных в Redux. Эти подходы включают использование асинхронных санков для получения данных, диспетчеризацию действий с результатами, управление состоянием загрузки запросов в хранилище и нормализацию кэшированных данных для упрощения поиска и обновления отдельных элементов по ID.
В этом разделе мы рассмотрим, как использовать RTK Query — решение для получения и кэширования данных, созданное для Redux-приложений, и увидим, как оно упрощает процесс получения данных и их использования в компонентах.
Обзор RTK Query
RTK Query — это мощный инструмент для получения и кэширования данных. Он разработан для упрощения типичных сценариев загрузки данных в веб-приложениях, избавляя от необходимости самостоятельно писать логику получения и кэширования данных.
RTK Query входит в пакет Redux Toolkit, и его функциональность построена поверх других API Redux Toolkit. Мы рекомендуем RTK Query как стандартный подход к получению данных в Redux-приложениях.
Мотивация
Веб-приложениям обычно требуется получать данные с сервера для их отображения. Также им часто необходимо обновлять эти данные, отправлять изменения на сервер и поддерживать синхронизацию кэшированных данных на клиенте с данными на сервере. Это усложняется необходимостью реализации других поведений, используемых в современных приложениях:
-
Отслеживание состояния загрузки для отображения индикаторов
-
Предотвращение дублирующих запросов одних и тех же данных
-
Оптимистичные обновления для ускорения отклика интерфейса
-
Управление временем жизни кэша при взаимодействии пользователя с интерфейсом
Мы уже видели, как можно реализовать эти поведения с помощью Redux Toolkit.
Однако изначально Redux не включал встроенных средств для полного решения этих задач. Даже при использовании createAsyncThunk вместе с createSlice остаётся значительный объём ручной работы: создание асинхронного санка, выполнение запроса, извлечение нужных полей из ответа, добавление полей состояния загрузки, обработчиков в extraReducers для случаев pending/fulfilled/rejected и написание правильных обновлений состояния.
Со временем сообщество React пришло к пониманию, что «загрузка и кэширование данных» — это действительно отдельная задача, отличная от «управления состоянием». Хотя вы можете использовать библиотеку для управления состоянием, такую как Redux, для кэширования данных, варианты использования достаточно различны, и стоит применять инструменты, специально созданные для загрузки данных.
Проблемы состояния на сервере
Стоит процитировать отличное объяснение со страницы документации React Query «Мотивация»:
Хотя большинство традиционных библиотек для управления состоянием отлично подходят для работы с состоянием на клиенте, они не так хороши для работы с асинхронным состоянием или состоянием на сервере. Это связано с тем, что состояние на сервере совершенно иное. Для начала:
- Сохраняется удалённо в месте, которое вы не контролируете
- Требует асинхронных API для загрузки и обновления
- Подразумевает совместное владение и может быть изменено другими без вашего ведома
- Может устареть в ваших приложениях, если не быть осторожным
Как только вы поймёте природу состояния на сервере в вашем приложении, возникнут ещё большие трудности, например:
- Кэширование... (возможно, самая сложная вещь в программировании)
- Устранение дублирования запросов на одни и те же данные в один запрос
- Фоновое обновление устаревших данных
- Определение, когда данные устарели
- Отражение обновлений данных как можно быстрее
- Оптимизации производительности, такие как постраничная загрузка и ленивая загрузка данных
- Управление памятью и сборкой мусора для состояния на сервере
- Мемоизация результатов запросов с совместным использованием структур
Отличия RTK Query
RTK Query вдохновлён другими инструментами, которые предложили решения для загрузки данных, такими как Apollo Client, React Query, Urql и SWR, но добавляет уникальный подход к дизайну API:
-
Логика загрузки и кэширования данных построена поверх API
createSliceиcreateAsyncThunkиз Redux Toolkit -
Поскольку Redux Toolkit не привязан к UI, функциональность RTK Query можно использовать с любым слоем представления: Angular, Vue или ванильным JS, а не только с React
-
Конечные точки API определяются заранее, включая генерацию параметров запроса из аргументов и преобразование ответов для кэширования
-
RTK Query может генерировать React-хуки, которые инкапсулируют весь процесс загрузки данных, предоставляют компонентам поля
dataиisFetchingи управляют жизненным циклом кэшированных данных при монтировании и размонтировании компонентов -
RTK Query предоставляет опции «жизненного цикла записи кэша» для реализации сценариев, например потокового обновления кэша через websocket после первоначальной загрузки данных
-
У нас есть генератор кода для создания определений API RTK Query из OpenAPI-схем
-
Наконец, RTK Query полностью написан на TypeScript и разработан для обеспечения отличного опыта работы с TS
Что включено
API
RTK Query включён в установку основного пакета Redux Toolkit. Он доступен через одну из двух точек входа ниже:
// UI-agnostic entry point with the core logic
import { createApi } from '@reduxjs/toolkit/query'
// React-specific entry point that automatically generates
// hooks corresponding to the defined endpoints
import { createApi } from '@reduxjs/toolkit/query/react'
RTK Query в основном состоит из двух API:
-
createApi(): Ядро функциональности RTK Query. Позволяет определить набор конечных точек (endpoints), описывающих получение данных из различных источников, включая конфигурацию запросов и преобразования данных. В большинстве случаев следует использовать её один раз на приложение, придерживаясь правила "один API-слой на каждый базовый URL". -
fetchBaseQuery(): Небольшая обёртка вокругfetch, предназначенная для упрощения HTTP-запросов. RTK Query можно использовать для кэширования результата любого асинхронного запроса, но поскольку HTTP-запросы — наиболее распространённый вариант использования,fetchBaseQueryпредоставляет поддержку HTTP из коробки.
Размер бандла
RTK Query добавляет фиксированный одноразовый объем к размеру бандла вашего приложения. Поскольку RTK Query построена поверх Redux Toolkit и React-Redux, добавленный размер зависит от того, используете ли вы их уже в приложении. Ориентировочные размеры минифицированных+gzip бандлов:
-
Если вы уже используете RTK: ~9 КБ для RTK Query и ~2 КБ для хуков.
-
Если вы не используете RTK:
- Без React: 17 КБ для RTK + зависимости + RTK Query
- С React: 19 КБ + React-Redux (peer-зависимость)
Добавление дополнительных конечных точек (endpoints) должно увеличивать размер лишь пропорционально фактическому коду внутри определений endpoints, который обычно составляет несколько байт.
Функциональность RTK Query быстро компенсирует добавленный размер бандла, а устранение ручной реализации логики получения данных в большинстве нетривиальных приложений даст чистый выигрыш в размере.
Мышление в терминах кэширования RTK Query
Redux всегда делал акцент на предсказуемости и явном поведении. В Redux нет "магии" — вы должны понимать происходящее в приложении, потому что вся логика Redux следует базовым шаблонам: диспетчеризация экшенов и обновление состояния через редюсеры. Иногда это требует написания большего кода, но компромисс в том, что поток данных и поведение остаются предельно ясными.
Базовые API Redux Toolkit не меняют фундаментальный поток данных в Redux-приложении. Вы по-прежнему диспетчеризуете экшены и пишете редюсеры, просто с меньшим объёмом кода. RTK Query работает аналогично. Это дополнительный уровень абстракции, но внутри она выполняет те же шаги, что мы уже видели для управления асинхронными запросами и их ответами — использует санки для запросов, диспетчеризует экшены с результатами и обрабатывает их в редюсерах для кэширования данных.
Однако при использовании RTK Query происходит смена парадигмы. Мы больше не думаем о "управлении состоянием" как таковом. Вместо этого мы начинаем мыслить в терминах "управления кэшированными данными". Вместо написания редюсеров мы фокусируемся на определении: "откуда берутся эти данные?", "как отправлять это обновление?", "когда перезапрашивать кэш?" и "как обновлять кэшированные данные?". То, как эти данные получаются, хранятся и извлекаются, становится деталью реализации, о которой нам больше не нужно беспокоиться.
Далее мы увидим, как эта смена парадигмы применяется на практике.
Настройка RTK Query
Наше демо-приложение уже работает, но теперь мы перенесём всю асинхронную логику на RTK Query. В процессе мы рассмотрим все основные возможности RTK Query, а также миграцию существующего кода с createAsyncThunk и createSlice на API RTK Query.
Определение API-среза
Ранее мы создавали отдельные "срезы" для каждого типа данных: посты, пользователи, уведомления. Каждый срез имел собственный редюсер, определял свои экшены и санки, а также хранил записи своего типа данных отдельно.
В RTK Query логика управления кэшированными данными централизована в едином "API-срезе" на приложение. Подобно тому, как у вас есть единое Redux-хранилище на приложение, теперь у нас есть единый срез для всех кэшированных данных.
Начнём с создания файла apiSlice.ts. Поскольку он не относится к уже существующим "фичам", добавим новую папку features/api/ и поместим туда apiSlice.ts. Заполним файл API-среза, а затем разберём его содержимое:
// Import the RTK Query methods from the React-specific entry point
import { createApi, fetchBaseQuery } from '@reduxjs/toolkit/query/react'
// Use the `Post` type we've already defined in `postsSlice`,
// and then re-export it for ease of use
import type { Post } from '@/features/posts/postsSlice'
export type { Post }
// Define our single API slice object
export const apiSlice = createApi({
// The cache reducer expects to be added at `state.api` (already default - this is optional)
reducerPath: 'api',
// All of our requests will have URLs starting with '/fakeApi'
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
// The "endpoints" represent operations and requests for this server
endpoints: builder => ({
// The `getPosts` endpoint is a "query" operation that returns data.
// The return value is a `Post[]` array, and it takes no arguments.
getPosts: builder.query<Post[], void>({
// The URL for the request is '/fakeApi/posts'
query: () => '/posts'
})
})
})
// Export the auto-generated hook for the `getPosts` query endpoint
export const { useGetPostsQuery } = apiSlice
Функциональность RTK Query основана на едином методе под названием createApi. Все API Redux Toolkit, которые мы рассматривали ранее, не зависят от UI-слоя и могут использоваться с любым интерфейсом. Ядро RTK Query работает аналогично. Однако RTK Query также включает React-специфичную версию createApi, и поскольку мы используем RTK совместно с React, нам необходимо применять её для использования преимуществ интеграции RTK с React. Поэтому мы импортируем из '@reduxjs/toolkit/query/react' явно.
В вашем приложении должен присутствовать только один вызов createApi. Этот единый API-слой должен содержать все определения конечных точек, взаимодействующих с одним базовым URL. Например, конечные точки /api/posts и /api/users получают данные с одного сервера, поэтому они должны находиться в одном API-слое. Если приложение получает данные с нескольких серверов, вы можете либо указывать полные URL в каждой конечной точке, либо (при крайней необходимости) создавать отдельные API-слои для каждого сервера.
Конечные точки обычно определяются непосредственно внутри вызова createApi. Если требуется распределить конечные точки по нескольким файлам, см. раздел «Внедрение конечных точек» в Части 8 документации!
Параметры API-слоя
При вызове createApi обязательными являются два поля:
-
baseQuery: функция, умеющая получать данные с сервера. RTK Query включаетfetchBaseQuery— обёртку над стандартнойfetch(), обрабатывающую типичные HTTP-запросы и ответы. При создании экземпляраfetchBaseQueryможно передать базовый URL для всех запросов и переопределить поведение (например, модифицировать заголовки). Вы можете создавать кастомные базовые запросы для настройки обработки ошибок или аутентификации. -
endpoints: набор операций для взаимодействия с сервером. Конечные точки могут быть queries (возвращают данные для кэширования) или mutations (отправляют обновления на сервер). Они определяются через функцию обратного вызова, принимающую параметрbuilderи возвращающую объект с определениями конечных точек черезbuilder.query()иbuilder.mutation().
createApi также принимает поле reducerPath, определяющее путь к срезу состояния для редюсера. В отличие от срезов вроде postsSlice (для которых нет гарантии, что они будут обновлять state.posts — мы могли подключить редюсер в любом месте состояния, например someOtherField: postsReducer), здесь createApi ожидает, что мы укажем, где будет храниться кэш. Если опция reducerPath не указана, используется значение по умолчанию 'api' — все данные кэша RTKQ будут храниться в state.api.
Если вы забудете добавить редюсер в хранилище или подключите его не по пути, указанному в reducerPath, RTKQ выведет ошибку для исправления.
Определение конечных точек
Базовый путь для всех запросов определён как '/fakeApi' в fetchBaseQuery.
На первом этапе добавим конечную точку для получения полного списка постов с фейкового сервера. Создадим конечную точку getPosts, определив её как query endpoint через builder.query(). Этот метод принимает множество опций для настройки запросов и обработки ответов. Пока достаточно указать query с функцией, возвращающей строку пути: () => '/posts'.
По умолчанию конечные точки запросов используют HTTP-запрос типа GET, но вы можете переопределить это поведение, возвращая объект вида {url: '/posts', method: 'POST', body: newPost} вместо строки с URL. Таким же способом можно определить другие параметры запроса, например настроить заголовки.
Для использования с TypeScript функции определения конечных точек builder.query() и builder.mutation() принимают два дженерик-аргумента: <ReturnType, ArgumentType>. Например, конечная точка для получения покемона по имени может выглядеть так: getPokemonByName: builder.query<Pokemon, string>(). Если конечная точка не принимает аргументов, используйте тип void, например: getAllPokemon: builder.query<Pokemon[], void>().
Экспорт срезов API и хуков
В наших предыдущих функциях createSlice нам нужно было экспортировать только создатели действий и редьюсеры слайса, потому что именно эти части слайсов требуются в других файлах. С RTK Query мы обычно экспортируем весь объект «API-слайса» целиком, поскольку он содержит несколько полей, которые могут быть полезны.
Наконец, обратите внимание на последнюю строку этого файла. Откуда берется значение useGetPostsQuery?
Интеграция RTK Query с React автоматически генерирует React-хуки для каждой определенной нами конечной точки! Эти хуки инкапсулируют процесс отправки запроса при монтировании компонента и перерисовки компонента по мере обработки запроса и поступления данных. Мы можем экспортировать эти хуки из файла среза API для использования в React-компонентах.
Хуки автоматически именуются по стандартному соглашению:
-
use— стандартный префикс для React-хуков -
Название конечной точки с заглавной буквы
-
Тип конечной точки:
QueryилиMutation
В нашем случае конечная точка называется getPosts и является запросом (query), поэтому сгенерированный хук — useGetPostsQuery.
Настройка хранилища
Теперь нам нужно подключить срез API к нашему Redux-хранилищу. Мы можем изменить существующий файл store.ts, добавив редьюсер кеша среза API в состояние. Кроме того, срез API генерирует пользовательский middleware, который необходимо добавить в хранилище. Этот middleware обязательно должен быть добавлен — он управляет временем жизни и сроком действия кеша.
import { configureStore } from '@reduxjs/toolkit'
import { apiSlice } from '@/features/api/apiSlice'
import authReducer from '@/features/auth/authSlice'
import postsReducer from '@/features/posts/postsSlice'
import usersReducer from '@/features/users/usersSlice'
import notificationsReducer from '@/features/notifications/notificationsSlice'
import { listenerMiddleware } from './listenerMiddleware'
export const store = configureStore({
// Pass in the root reducer setup as the `reducer` argument
reducer: {
auth: authReducer,
posts: postsReducer,
users: usersReducer,
notifications: notificationsReducer,
[apiSlice.reducerPath]: apiSlice.reducer
},
middleware: getDefaultMiddleware =>
getDefaultMiddleware()
.prepend(listenerMiddleware.middleware)
.concat(apiSlice.middleware)
})
Мы можем повторно использовать поле apiSlice.reducerPath как вычисляемый ключ в параметре reducer, чтобы гарантировать, что редьюсер кеширования добавлен в нужное место.
Как мы видели при добавлении middleware для прослушивания, нам нужно сохранить все существующие стандартные middleware, такие как redux-thunk, и добавить middleware среза API после них. Мы уже вызываем getDefaultMiddleware() и помещаем middleware для прослушивания в начало, поэтому можем вызвать .concat(apiSlice.middleware) для добавления в конец.
Отображение постов с помощью запросов
Использование хуков запросов в компонентах
Теперь, когда мы определили срез API и добавили его в хранилище, мы можем импортировать сгенерированный хук useGetPostsQuery в наш компонент <PostsList>.
Сейчас <PostsList> явно импортирует useSelector, useDispatch и useEffect, читает данные постов и состояние загрузки из хранилища, а также отправляет санк fetchPosts() при монтировании для загрузки данных. Хук useGetPostsQueryHook заменяет все это!
Вот как выглядит <PostsList> при использовании этого хука:
import React from 'react'
import { Link } from 'react-router-dom'
import { Spinner } from '@/components/Spinner'
import { TimeAgo } from '@/components/TimeAgo'
import { useGetPostsQuery, Post } from '@/features/api/apiSlice'
import { PostAuthor } from './PostAuthor'
import { ReactionButtons } from './ReactionButtons'
// Go back to passing a `post` object as a prop
interface PostExcerptProps {
post: Post
}
function PostExcerpt({ post }: PostExcerptProps) {
return (
<article className="post-excerpt" key={post.id}>
<h3>
<Link to={`/posts/${post.id}`}>{post.title}</Link>
</h3>
<div>
<PostAuthor userId={post.user} />
<TimeAgo timestamp={post.date} />
</div>
<p className="post-content">{post.content.substring(0, 100)}</p>
<ReactionButtons post={post} />
</article>
)
}
export const PostsList = () => {
// Calling the `useGetPostsQuery()` hook automatically fetches data!
const {
data: posts = [],
isLoading,
isSuccess,
isError,
error
} = useGetPostsQuery()
let content: React.ReactNode
// Show loading states based on the hook status flags
if (isLoading) {
content = <Spinner text="Loading..." />
} else if (isSuccess) {
content = posts.map(post => <PostExcerpt key={post.id} post={post} />)
} else if (isError) {
content = <div>{error.toString()}</div>
}
return (
<section className="posts-list">
<h2>Posts</h2>
{content}
</section>
)
}
Концептуально <PostsList> по-прежнему выполняет ту же работу, но мы смогли заменить несколько вызовов useSelector и отправку через useEffect одним вызовом useGetPostsQuery().
(Обратите внимание, что на этом этапе в приложении возникнут некоторые несоответствия: часть кода будет по-прежнему обращаться к существующему слайсу state.posts за данными, а новый код — читать из RTK Query. Это ожидаемо, и мы будем исправлять эти несоответствия по мере продвижения.)
Ранее мы выбирали список ID постов из хранилища, передавали ID каждого поста в компонент <PostExcerpt> и отдельно выбирали каждый объект Post из хранилища. Поскольку массив posts уже содержит все объекты постов, мы вернулись к передаче самих объектов постов через пропсы.
Для доступа к кешированным данным в компонентах следует использовать хуки запросов — не нужно писать собственные вызовы useSelector для получения данных или useEffect для инициирования запросов!
Объекты результатов хуков запросов
Каждый сгенерированный хук запроса возвращает объект "result" со следующими полями:
-
data: фактическое содержимое ответа сервера для последней успешной записи в кеше. Это поле будетundefined, пока ответ не получен. -
currentData: содержимое ответа для текущих аргументов запроса. Может статьundefined, если аргументы изменятся и начнётся новый запрос (при отсутствии существующей кеш-записи). -
isLoading: логическое значение, указывающее, что хук в данный момент делает первый запрос к серверу (поскольку данных ещё нет). (Примечание: если параметры изменяются для запроса других данных,isLoadingостанется false.) -
isFetching: логическое значение, указывающее, что хук в данный момент делает любой запрос к серверу -
isSuccess: логическое значение, указывающее, что запрос завершился успешно и доступны кешированные данные (т.е.dataтеперь должен быть определён) -
isError: логическое значение, указывающее, что последний запрос завершился ошибкой -
error: сериализованный объект ошибки
Обычно поля объекта результата деструктурируют, а data переименовывают в более конкретную переменную (например, posts). Затем используют статусные флаги и поля data/error для рендеринга нужного UI. Однако в старых версиях TypeScript может потребоваться сохранить исходный объект и обращаться к флагам как result.isSuccess, чтобы TS корректно определял валидность data.
Поля состояния загрузки
Обратите внимание: isLoading и isFetching — разные флаги с разным поведением. Выбор между ними зависит от того, когда и как нужно показывать состояния загрузки в UI. Например:
isLoading— для показа скелетона при первой загрузке страницыisFetching— для показа спиннера или затемнения существующих результатов при любом запросе (например, при выборе пользователем разных элементов)
Аналогично data и currentData меняются в разное время. Обычно используют data, но currentData даёт больше гибкости. Например:
- Для полупрозрачного отображения данных при повторном запросе используйте
dataвместе сisFetching(так какdataне изменится до завершения нового запроса) - Для очистки UI до завершения нового запроса используйте
currentData(чтобы показывать только данные для текущих аргументов)
Сортировка постов
К сожалению, посты теперь отображаются в неправильном порядке. Ранее мы сортировали их по дате на уровне редюсера через опцию createEntityAdapter. Поскольку API-слайс кеширует точный массив с сервера, сортировка не применяется — порядок соответствует ответу сервера.
Есть несколько вариантов обработки этого. Сейчас мы выполним сортировку внутри самого компонента <PostsList>, а о других вариантах и их компромиссах поговорим позже.
Мы не можем просто вызвать posts.sort() напрямую, потому что Array.sort() изменяет исходный массив, поэтому сначала нужно создать его копию. Чтобы избежать повторной сортировки при каждом ререндере, мы можем выполнить сортировку в хуке useMemo(). Также зададим для posts значение по умолчанию — пустой массив на случай undefined, чтобы всегда иметь массив для сортировки.
// omit setup
export const PostsList = () => {
const {
data: posts = [],
isLoading,
isSuccess,
isError,
error
} = useGetPostsQuery()
const sortedPosts = useMemo(() => {
const sortedPosts = posts.slice()
// Sort posts in descending chronological order
sortedPosts.sort((a, b) => b.date.localeCompare(a.date))
return sortedPosts
}, [posts])
let content
if (isLoading) {
content = <Spinner text="Loading..." />
} else if (isSuccess) {
content = sortedPosts.map(post => <PostExcerpt key={post.id} post={post} />)
} else if (isError) {
content = <div>{error.toString()}</div>
}
// omit rendering
}
Отображение отдельных записей
Мы обновили <PostsList> для получения списка всех записей и отображаем части каждого Post внутри списка. Но если нажать "View Post" для любой записи, компонент <SinglePostPage> не найдёт её в старом срезе state.posts и покажет ошибку "Post not found!". Нам нужно обновить <SinglePostPage> для работы с RTK Query.
Есть несколько способов это сделать. Один вариант — заставить <SinglePostPage> вызывать тот же хук useGetPostsQuery(), получать весь массив записей и находить нужный Post. У хуков запросов также есть опция selectFromResult, позволяющая выполнить этот поиск внутри хука — мы увидим это позже.
Вместо этого мы добавим новую конечную точку для запроса одной записи по её ID. Это несколько избыточно, но покажет, как RTK Query настраивает запросы на основе аргументов.
Добавление конечной точки для одной записи
В файле apiSlice.ts добавим новое определение конечной точки getPost (без 's'):
export const apiSlice = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
endpoints: builder => ({
getPosts: builder.query<Post[], void>({
query: () => '/posts'
}),
getPost: builder.query<Post, string>({
query: postId => `/posts/${postId}`
})
})
})
export const { useGetPostsQuery, useGetPostQuery } = apiSlice
Конечная точка getPost похожа на getPosts, но параметр query отличается. Здесь query принимает аргумент postId, используя этот postId для построения URL сервера. Так мы можем запросить конкретный объект Post.
Это также генерирует новый хук useGetPostQuery, который мы экспортируем.
Аргументы запросов и ключи кэширования
Сейчас <SinglePostPage> читает запись Post из state.posts по ID. Обновим его для вызова useGetPostQuery с аналогичным состоянием загрузки, как в основном списке.
// omit some imports
import { useGetPostQuery } from '@/features/api/apiSlice'
import { selectCurrentUsername } from '@/features/auth/authSlice'
export const SinglePostPage = () => {
const { postId } = useParams()
const currentUsername = useAppSelector(selectCurrentUsername)
const { data: post, isFetching, isSuccess } = useGetPostQuery(postId!)
let content: React.ReactNode
const canEdit = currentUsername === post?.user
if (isFetching) {
content = <Spinner text="Loading..." />
} else if (isSuccess) {
content = (
<article className="post">
<h2>{post.title}</h2>
<div>
<PostAuthor userId={post.user} />
<TimeAgo timestamp={post.date} />
</div>
<p className="post-content">{post.content}</p>
<ReactionButtons post={post} />
{canEdit && (
<Link to={`/editPost/${post.id}`} className="button">
Edit Post
</Link>
)}
</article>
)
}
return <section>{content}</section>
}
Обратите внимание: мы берём postId из параметров роутера и передаём его в useGetPostQuery. Хук использует его для построения URL и получения конкретного объекта Post.
Как же кэшируются эти данные? Нажмём "View Post" для записи и посмотрим состояние Redux-хранилища:
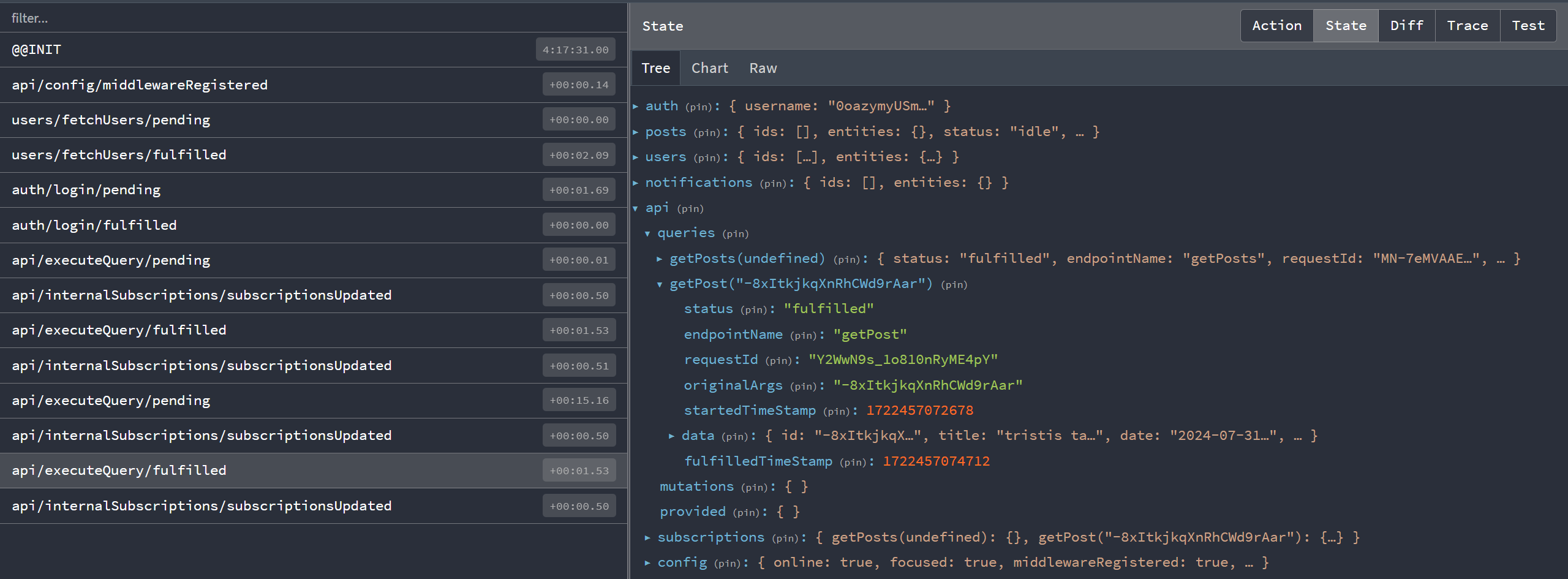
Видим срез state.api, как ожидалось из настройки хранилища. Внутри раздела queries два элемента: ключ getPosts(undefined) содержит метаданные и ответ для запроса через getPosts, а getPost('abcd1234') — для конкретного запроса этой записи.
RTK Query создаёт "ключ кэша" для каждой уникальной комбинации конечной точки и аргументов, храня результаты отдельно. Вы можете многократно использовать один хук запроса с разными параметрами, и каждый результат будет закэширован отдельно в Redux-хранилище.
Если вам нужны одни и те же данные в нескольких компонентах, просто вызывайте один и тот же хук запроса с одинаковыми аргументами в каждом компоненте! Например, вы можете вызвать useGetPostQuery('123') в трёх разных компонентах, и RTK Query гарантирует, что данные будут загружены только один раз, а каждый компонент перерендерится при необходимости.
Также важно отметить, что параметр запроса должен быть единичным значением! Если вам нужно передать несколько параметров, вы должны передать объект с несколькими полями (точно так же, как в createAsyncThunk). RTK Query выполнит "поверхностное устойчивое" сравнение полей и повторно загрузит данные при изменении любого из них.
Обратите внимание, что имена действий в списке слева стали более общими и менее описательными: api/executeQuery/fulfilled вместо posts/fetchPosts/fulfilled. Это компромисс при использовании дополнительного слоя абстракции. Отдельные действия действительно содержат имя конкретного эндпоинта в action.meta.arg.endpointName, но его не так легко увидеть в истории действий.
В Redux DevTools есть вкладка "RTK Query", которая специально отображает данные RTK Query в более удобном формате, фокусируясь на кешированных записях вместо сырой структуры состояния Redux. Это включает информацию по каждому эндпоинту и результату кеширования, статистику по времени запросов и многое другое:
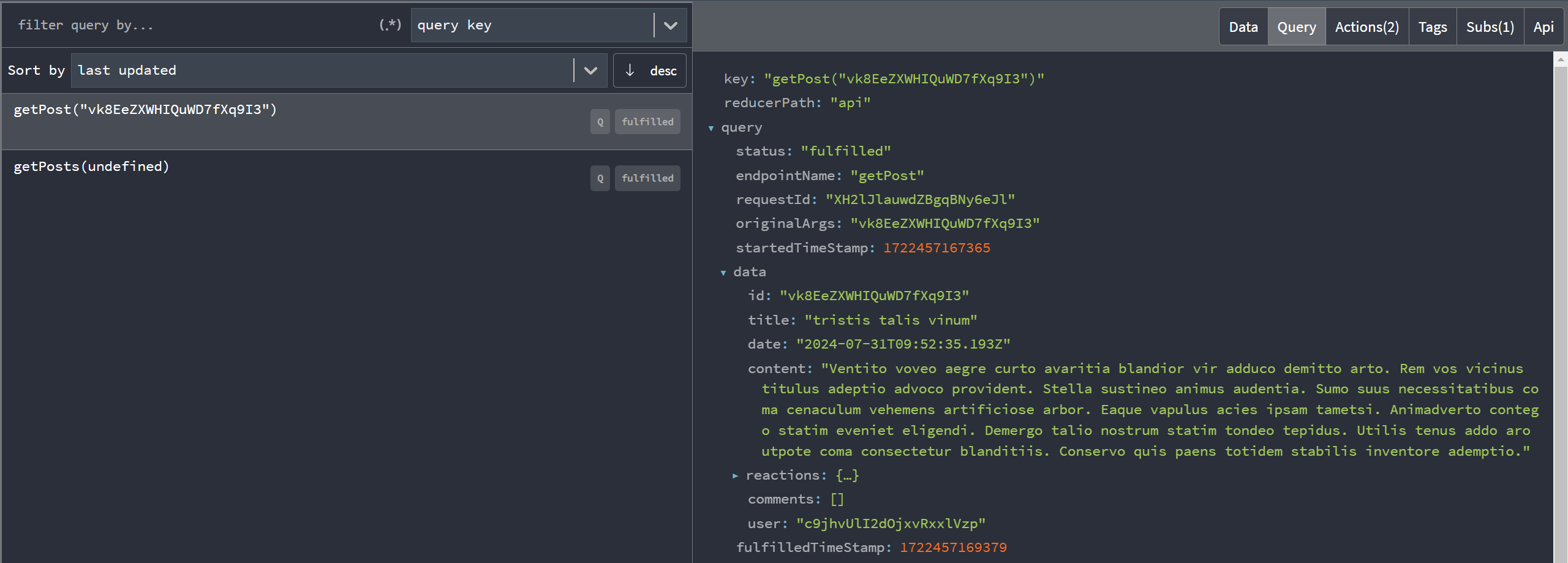
Вы также можете посмотреть live-демо инструментов разработки RTK Query:
Создание постов через мутации
Мы увидели, как можно получать данные с сервера через "запрашивающие" эндпоинты, но как отправлять обновления на сервер?
RTK Query позволяет определять мутационные эндпоинты для обновления данных на сервере. Добавим мутацию, которая позволит создавать новые посты.
Добавление мутационного эндпоинта для новых постов
Добавление мутационного эндпоинта очень похоже на добавление запрашивающего. Главное отличие — мы определяем эндпоинт через builder.mutation() вместо builder.query(). Также нам нужно изменить HTTP-метод на 'POST' и предоставить тело запроса.
Мы экспортируем существующий TS-тип NewPost из postsSlice.ts, затем используем его как тип аргумента для этой мутации, поскольку именно его передаёт наш компонент.
import { createApi, fetchBaseQuery } from '@reduxjs/toolkit/query/react'
import type { Post, NewPost } from '@/features/posts/postsSlice'
export type { Post }
export const apiSlice = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
endpoints: builder => ({
getPosts: builder.query<Post[], void>({
query: () => '/posts'
}),
getPost: builder.query<Post, string>({
query: postId => `/posts/${postId}`
}),
addNewPost: builder.mutation<Post, NewPost>({
query: initialPost => ({
// The HTTP URL will be '/fakeApi/posts'
url: '/posts',
// This is an HTTP POST request, sending an update
method: 'POST',
// Include the entire post object as the body of the request
body: initialPost
})
})
})
})
export const {
useGetPostsQuery,
useGetPostQuery,
useAddNewPostMutation
} = apiSlice
Как и с запрашивающими эндпоинтами, мы указываем TS-типы: мутация возвращает полный объект Post, а принимает частичное значение NewPost в качестве аргумента.
Здесь наша опция query возвращает объект {url, method, body}, что позволяет указать HTTP-метод POST и каким должно быть содержимое body. Поскольку мы используем fetchBaseQuery для запросов, поле body автоматически сериализуется в JSON. (И да, слово "post" встречается в этом примере слишком часто :) )
Как и с запрашивающими эндпоинтами, API-слайс автоматически генерирует React-хук для мутационного эндпоинта — в данном случае useAddNewPostMutation.
Использование мутационных хуков в компонентах
Наш <AddPostForm> уже диспатчит асинхронную санк для добавления поста при клике на кнопку "Save Post". Для этого он импортирует useDispatch и санк addNewPost. Мутационные хуки заменяют оба этих элемента, а схема использования практически идентична:
import React from 'react'
import { useAppSelector } from '@/app/hooks'
import { useAddNewPostMutation } from '@/features/api/apiSlice'
import { selectCurrentUsername } from '@/features/auth/authSlice'
// omit field types
export const AddPostForm = () => {
const userId = useAppSelector(selectCurrentUsername)!
const [addNewPost, { isLoading }] = useAddNewPostMutation()
const handleSubmit = async (e: React.FormEvent<AddPostFormElements>) => {
// Prevent server submission
e.preventDefault()
const { elements } = e.currentTarget
const title = elements.postTitle.value
const content = elements.postContent.value
const form = e.currentTarget
try {
await addNewPost({ title, content, user: userId }).unwrap()
form.reset()
} catch (err) {
console.error('Failed to save the post: ', err)
}
}
return (
<section>
<h2>Add a New Post</h2>
<form onSubmit={handleSubmit}>
<label htmlFor="postTitle">Post Title:</label>
<input
type="text"
id="postTitle"
name="postTitle"
defaultValue=""
required
/>
<label htmlFor="postContent">Content:</label>
<textarea
id="postContent"
name="postContent"
defaultValue=""
required
/>
<button disabled={isLoading}>Save Post</button>
</form>
</section>
)
}
Мутационные хуки возвращают массив с двумя значениями:
-
Первое значение — "триггер-функция". При вызове она отправляет запрос на сервер с переданным аргументом. Фактически это санк, уже обёрнутый для немедленного диспатча.
-
Второе значение — объект с метаданными о текущем выполняемом запросе (если есть). Включает флаг
isLoading, указывающий на выполнение запроса.
Мы можем заменить существующее thunk-действие и состояние загрузки компонента на триггер-функцию и флаг isLoading из хука useAddNewPostMutation, остальная часть компонента остаётся без изменений.
Как и при предыдущем thunk-действии, мы вызываем addNewPost с начальным объектом поста. Это возвращает специальный Promise с методом .unwrap(), и мы можем использовать await addNewPost().unwrap() для обработки потенциальных ошибок через стандартный блок try/catch. (Это выглядит так же, как ранее с createAsyncThunk, потому что это то же самое — внутри RTK Query использует createAsyncThunk)
Обновление кэшированных данных
Когда мы нажимаем "Save Post", в Network-вкладке браузерных DevTools видно успешное выполнение HTTP-запроса POST. Но новый пост не отображается в нашем компоненте <PostsList> при возвращении туда. Состояние Redux-хранилища не изменилось, а кэшированные данные остались прежними.
Нам нужно заставить RTK Query обновить кэшированный список постов, чтобы отображался добавленный пост.
Ручное обновление постов
Первый вариант — принудительно обновить данные для определённой конечной точки. Это не лучший подход для реального приложения, но мы попробуем его как промежуточный шаг.
Результат хука запроса включает функцию refetch для принудительного обновления. Мы можем временно добавить кнопку "Обновить посты" в <PostsList> и нажать её после добавления нового поста:
export const PostsList = () => {
const {
data: posts = [],
isLoading,
isSuccess,
isError,
error,
refetch
} = useGetPostsQuery()
// omit content
return (
<section className="posts-list">
<h2>Posts</h2>
<button onClick={refetch}>Refetch Posts</button>
{content}
</section>
)
}
Теперь, добавив новый пост, дождавшись завершения и нажав "Обновить посты", мы увидим новый пост в списке.
К сожалению, нет индикатора процесса обновления. Было бы полезно показать что-нибудь, указывающее на выполнение запроса.
Ранее мы видели, что хуки запроса имеют флаг isLoading, который равен true при первом запросе данных, и флаг isFetching, который равен true во время любого запроса данных. Мы могли бы использовать флаг isFetching и заменять весь список постов спиннером загрузки при повторном запросе. Но это может раздражать — зачем скрывать уже существующие посты?
Вместо этого мы можем сделать существующий список полупрозрачным, указывая на устаревание данных, но оставить его видимым во время обновления. После завершения запроса список возвращается в нормальное состояние.
import classnames from 'classnames'
import { useGetPostsQuery, Post } from '@/features/api/apiSlice'
// omit other imports and PostExcerpt
export const PostsList = () => {
const {
data: posts = [],
isLoading,
isFetching,
isSuccess,
isError,
error,
refetch
} = useGetPostsQuery()
const sortedPosts = useMemo(() => {
const sortedPosts = posts.slice()
sortedPosts.sort((a, b) => b.date.localeCompare(a.date))
return sortedPosts
}, [posts])
let content: React.ReactNode
if (isLoading) {
content = <Spinner text="Loading..." />
} else if (isSuccess) {
const renderedPosts = sortedPosts.map(post => (
<PostExcerpt key={post.id} post={post} />
))
const containerClassname = classnames('posts-container', {
disabled: isFetching
})
content = <div className={containerClassname}>{renderedPosts}</div>
} else if (isError) {
content = <div>{error.toString()}</div>
}
// omit return
}
Добавив новый пост и нажав "Обновить посты", мы увидим полупрозрачный список постов на пару секунд, после чего он перерендерится с новым постом в начале.
Автоматическое обновление через инвалидацию кэша
Ручное обновление данных иногда необходимо, но не является оптимальным решением.
Мы знаем, что наш "сервер" содержит полный список постов, включая новый. Идеально, чтобы приложение автоматически обновляло кэш после завершения мутации — тогда клиентские данные гарантированно синхронизированы с сервером.
RTK Query позволяет связывать запросы и мутации через "теги" для автоматического обновления данных. "Тег" — это строка или объект-идентификатор типа данных. При инвалидации тега RTK Query автоматически обновляет связанные с ним конечные точки.
Базовая настройка тегов требует трёх шагов в API-слое:
-
Корневое поле
tagTypesв объекте API-слоя, объявляющее массив строк-идентификаторов (например'Post') -
Массив
providesTagsв конечных точках запросов, содержащий набор тегов для описания данных в этом запросе -
Массив
invalidatesTagsв конечных точках мутаций, содержащий набор тегов, которые инвалидируются при каждом выполнении мутации
Мы можем добавить один тег 'Post' в наш API-слайс, что позволит автоматически перезапрашивать конечную точку getPosts при каждом добавлении нового поста:
export const apiSlice = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
tagTypes: ['Post'],
endpoints: builder => ({
getPosts: builder.query<Post[], void>({
query: () => '/posts',
providesTags: ['Post']
}),
getPost: builder.query<Post, string>({
query: postId => `/posts/${postId}`
}),
addNewPost: builder.mutation<Post, NewPost>({
query: initialPost => ({
url: '/posts',
method: 'POST',
body: initialPost
}),
invalidatesTags: ['Post']
})
})
})
Это всё, что требуется! Теперь при клике на "Сохранить пост" компонент <PostsList> через пару секунд автоматически потускнеет, а затем перерендерится с новым постом вверху списка.
Обратите внимание, что строковый литерал 'Post' не имеет особого значения. Мы могли бы назвать его 'Fred', 'qwerty' или как угодно. Главное — использовать одинаковую строку в каждом поле, чтобы RTK Query понимал: "при этой мутации инвалидировать все конечные точки, содержащие такой же тег".
Итоги изученного
RTK Query абстрагирует детали управления загрузкой данных, кэшированием и состоянием загрузки. Это значительно упрощает код приложения, позволяя сосредоточиться на высокоуровневом поведении. Поскольку RTK Query использует те же API Redux Toolkit, мы можем отслеживать изменения состояния через Redux DevTools.
- RTK Query — решение для загрузки и кэширования данных, встроенное в Redux Toolkit
- Абстрагирует управление кэшированными серверными данными, устраняя необходимость писать логику для состояний загрузки, хранения результатов и выполнения запросов
- Основано на тех же паттернах Redux, что и асинхронные санки
- RTK Query использует единый "API-слайс" на приложение, создаваемый через
createApi- Предоставляет UI-агностичную и React-специфичную версии
createApi - API-слайс определяет несколько "конечных точек" для серверных операций
- Включает автогенерируемые React-хуки при использовании React-интеграции
- Предоставляет UI-агностичную и React-специфичную версии
- Конечные точки запросов позволяют загружать и кэшировать данные с сервера
- Хуки запросов возвращают значение
dataи флаги состояния загрузки - Запросы можно перезапускать вручную или автоматически через "теги" для инвалидации кэша
- Хуки запросов возвращают значение
- Конечные точки мутаций позволяют обновлять данные на сервере
- Хуки мутаций возвращают "триггер"-функцию для отправки запроса и флаги состояния
- Триггер возвращает Promise, который можно "развернуть" и ожидать через await
Что дальше?
RTK Query предоставляет надёжное поведение по умолчанию и множество опций для кастомизации управления запросами и работы с кэшем. В Части 8: Расширенные шаблоны RTK Query мы рассмотрим, как использовать эти опции для реализации оптимистичных обновлений и других полезных функций.