Redux 핵심 가이드, 파트 7: RTK Query 기초
이 페이지는 PageTurner AI로 번역되었습니다(베타). 프로젝트 공식 승인을 받지 않았습니다. 오류를 발견하셨나요? 문제 신고 →
- RTK Query가 Redux 앱에서 데이터 가져오기를 어떻게 간소화하는지
- RTK Query 설정 방법
- 기본 데이터 가져오기 및 업데이트 요청에 RTK Query 사용 방법
- Redux Toolkit 사용 패턴을 이해하기 위해 본 튜토리얼의 이전 섹션 완료
동영상 강좌를 선호한다면 RTK Query 창시자 Lenz Weber-Tronic의 무료 Egghead 강좌를 시청하세요 또는 첫 번째 강의를 바로 확인해보세요:
소개
파트 5: 비동기 로직과 데이터 가져오기와 파트 6: 성능 및 정규화에서 Redux와 함께 사용되는 데이터 가져오기 및 캐싱의 표준 패턴을 살펴봤습니다. 이러한 패턴에는 비동기 thunk를 사용한 데이터 가져오기, 결과와 함께 액션 디스패치, 스토어에서 요청 로딩 상태 관리, 개별 항목을 ID로 쉽게 조회하고 업데이트할 수 있도록 캐시 데이터 정규화 등이 포함됩니다.
이번 섹션에서는 Redux 애플리케이션을 위해 설계된 데이터 가져오기 및 캐싱 솔루션인 RTK Query 사용 방법을 살펴보고, 데이터 가져오기와 컴포넌트에서의 사용 과정이 어떻게 단순화되는지 확인해 보겠습니다.
RTK Query 개요
RTK Query는 강력한 데이터 가져오기 및 캐싱 도구입니다. 웹 애플리케이션에서 데이터를 로드하는 일반적인 경우를 단순화하도록 설계되었으며, 직접 데이터 가져오기 및 캐싱 로직을 작성할 필요를 없애줍니다.
RTK Query는 Redux Toolkit 패키지에 포함되어 있으며, 그 기능은 Redux Toolkit의 다른 API 위에 구축되었습니다. Redux 앱에서 데이터 가져오기를 위한 기본 접근 방식으로 RTK Query를 권장합니다.
도입 배경
웹 애플리케이션은 일반적으로 표시할 데이터를 서버에서 가져와야 합니다. 또한 해당 데이터를 업데이트하고, 변경 사항을 서버에 전송하며, 클라이언트의 캐시 데이터를 서버 데이터와 동기화 상태로 유지해야 합니다. 현대 애플리케이션에서 사용되는 다음 동작들을 구현해야 하므로 이 과정은 더 복잡해집니다:
-
UI 스피너 표시를 위한 로딩 상태 추적
-
동일한 데이터에 대한 중복 요청 방지
-
UI 반응성을 높이기 위한 낙관적 업데이트
-
사용자와 UI가 상호작용할 때 캐시 수명 관리
이러한 동작들을 Redux Toolkit으로 구현하는 방법은 이미 살펴봤습니다.
하지만 원래 Redux는 이러한 사용 사례를 완전히 해결하는 데 도움이 되는 내장 기능을 포함하지 않았습니다. createAsyncThunk와 createSlice를 함께 사용하더라도 요청 생성과 로딩 상태 관리에는 상당한 수작업이 필요합니다. 비동기 thunk 생성, 실제 요청 수행, 응답에서 관련 필드 추출, 로딩 상태 필드 추가, pending/fulfilled/rejected 사례를 처리하기 위한 extraReducers 핸들러 추가, 그리고 실제 상태 업데이트 작성까지 모두 직접 해야 합니다.
시간이 지나면서 React 커뮤니티는 "데이터 가져오기 및 캐싱"이 실제로 "상태 관리"와는 다른 관심사라는 점을 깨닫게 되었습니다. Redux와 같은 상태 관리 라이브러리를 사용해 데이터를 캐싱할 수 있지만, 사용 사례가 충분히 달라 데이터 가져오기 용도로 특화된 도구를 사용하는 것이 가치 있습니다.
서버 상태의 도전 과제
React Query의 "Motivation" 문서 페이지의 훌륭한 설명을 인용할 가치가 있습니다:
대부분의 기존 상태 관리 라이브러리는 클라이언트 상태 작업에는 훌륭하지만, 비동기 또는 서버 상태 작업에는 그렇지 않습니다. 이는 서버 상태가 근본적으로 다르기 때문입니다. 우선 서버 상태는:
- 사용자가 통제하거나 소유하지 않은 원격 위치에 유지됨
- 가져오기 및 업데이트를 위한 비동기 API가 필요함
- 공유 소유권을 의미하며 다른 사람이 모르게 변경될 수 있음
- 주의하지 않으면 애플리케이션에서 "구식"이 될 가능성 있음
애플리케이션에서 서버 상태의 특성을 이해하면 다음과 같은 더 많은 도전 과제가 발생합니다:
- 캐싱... (프로그래밍에서 가장 어려운 작업 중 하나)
- 동일한 데이터에 대한 여러 요청을 단일 요청으로 중복 제거
- 백그라운드에서 "구식" 데이터 업데이트
- 데이터가 "구식"인 시점 파악
- 데이터 업데이트를 가능한 빠르게 반영
- 페이징 및 지연 로딩과 같은 성능 최적화
- 서버 상태의 메모리 관리 및 가비지 컬렉션
- 구조적 공유로 쿼리 결과 메모이제이션
RTK Query의 차별점
RTK Query는 Apollo Client, React Query, Urql, SWR와 같은 데이터 가져오기 솔루션의 선구자로부터 영감을 받았지만 API 설계에 독특한 접근 방식을 추가합니다:
-
데이터 가져오기 및 캐싱 로직은 Redux Toolkit의
createSlice및createAsyncThunkAPI 위에 구축됨 -
Redux Toolkit이 UI에 구애받지 않으므로 RTK Query 기능은 React뿐만 아니라 Angular, Vue 또는 순수 JS와 같은 모든 UI 레이어에서 사용 가능
-
인수에서 쿼리 매개변수를 생성하고 캐싱을 위해 응답을 변환하는 방법을 포함해 API 엔드포인트를 사전 정의
-
RTK Query는 전체 데이터 가져오기 프로세스를 캡슐화하는 React 훅을 생성할 수 있으며, 컴포넌트에
data및isFetching필드를 제공하고 컴포넌트 마운트/언마운트 시 캐시된 데이터 수명 관리 -
RTK Query는 초기 데이터 가져오기 후 웹소켓 메시지를 통해 스트리밍 캐시 업데이트와 같은 사용 사례를 가능하게 하는 "캐시 엔트리 수명 주기" 옵션 제공
-
OpenAPI 스키마에서 RTK Query API 정의를 생성하는 코드 생성기 제공
-
마지막으로 RTK Query는 완전히 TypeScript로 작성되었으며 우수한 TS 사용 경험을 제공하도록 설계됨
포함 사항
API
RTK Query는 핵심 Redux Toolkit 패키지 설치에 포함됩니다. 다음 두 진입점 중 하나를 통해 사용 가능합니다:
// UI-agnostic entry point with the core logic
import { createApi } from '@reduxjs/toolkit/query'
// React-specific entry point that automatically generates
// hooks corresponding to the defined endpoints
import { createApi } from '@reduxjs/toolkit/query/react'
RTK Query는 주로 두 가지 API로 구성됩니다:
-
createApi(): RTK Query 기능의 핵심입니다. 일련의 엔드포인트에서 데이터를 검색하는 방법을 설명하는 엔드포인트 집합을 정의할 수 있게 해주며, 여기에는 데이터 가져오기 및 변환 방법에 대한 구성이 포함됩니다. 대부분의 경우 앱당 한 번만 사용해야 하며, 경험적으로 "기본 URL당 하나의 API 슬라이스"를 원칙으로 합니다[^1]. -
fetchBaseQuery():fetch를 간소화하는 작은 래퍼입니다. RTK Query는 모든 비동기 요청 결과를 캐시할 수 있지만, HTTP 요청이 가장 일반적인 사용 사례이므로fetchBaseQuery가 즉시 HTTP 지원을 제공합니다.
번들 크기
RTK Query는 앱의 번들 크기에 고정된 일회성 용량을 추가합니다. RTK Query가 Redux Toolkit과 React-Redux 위에 구축되므로, 추가되는 용량은 해당 라이브러리를 이미 사용 중인지 여부에 따라 달라집니다. 예상 min+gzip 번들 크기는 다음과 같습니다:
-
이미 RTK를 사용 중인 경우: RTK Query에 약 9kb, 훅에 약 2kb 추가
-
아직 RTK를 사용하지 않는 경우:
- React 미사용 시: RTK+의존성+RTK Query 17 kB
- React 사용 시: 19kB + peer dependency인 React-Redux
추가 엔드포인트 정의는 endpoints 내부의 실제 코드에 기반해 크기를 증가시키며, 일반적으로 몇 바이트 수준에 불과합니다.
RTK Query의 기능은 추가된 번들 크기를 빠르게 상쇄하며, 수동 데이터 가져오기 로직 제거로 인해 대부분의 실질적인 애플리케이션에서는 오히려 용량이 개선됩니다.
RTK Query 캐싱 사고방식
Redux는 항상 예측 가능성과 명시적 동작을 강조해 왔습니다. Redux에는 "마법"이 없습니다. 모든 Redux 로직이 액션 디스패치와 리듀서를 통한 상태 업데이트라는 동일한 기본 패턴을 따르기 때문에 애플리케이션 동작을 이해할 수 있어야 합니다. 이는 때로 더 많은 코드 작성을 요구하지만, 그 대가로 데이터 흐름과 동작이 매우 명확해집니다.
Redux Toolkit 핵심 API는 Redux 앱의 기본 데이터 흐름을 변경하지 않습니다. 여전히 액션을 디스패치하고 리듀서를 작성하되, 수동 로직 작성보다 적은 코드로 가능합니다. RTK Query도 마찬가지입니다. 추가적인 추상화 계층이지만, 내부적으로는 비동기 요청 관리에 이미 익숙한 단계를 정확히 수행합니다 - thunk로 비동기 요청 실행, 결과와 함께 액션 디스패치, 리듀서에서 액션 처리로 데이터 캐싱.
하지만 RTK Query 사용 시 사고방식의 전환 이 발생합니다. 더 이상 "상태 관리" 자체에 집중하지 않고, "캐시된 데이터 관리"에 초점을 맞춥니다. 리듀서를 직접 작성하기보다 **"데이터 출처는?", "업데이트 전송 방법은?", "캐시 재조회 시점은?", "캐시 업데이트 방식은?"**을 정의하게 됩니다. 데이터 가져오기/저장/조회 방식은 더 이상 신경 쓸 필요 없는 구현 세부사항이 됩니다.
이 사고방식 전환이 어떻게 적용되는지 계속 살펴보겠습니다.
RTK Query 설정하기
예시 애플리케이션은 이미 작동하지만, 이제 모든 비동기 로직을 RTK Query로 마이그레이션할 차례입니다. 진행 과정에서 RTK Query의 주요 기능 사용법과 기존 createAsyncThunk/createSlice 사용 사례를 RTK Query API로 전환하는 방법을 확인할 수 있습니다.
API 슬라이스 정의하기
이전에는 게시물(Posts), 사용자(Users), 알림(Notifications) 등 각 데이터 유형별로 별도 "슬라이스"를 정의했습니다. 각 슬라이스는 자체 리듀서를 보유하고, 고유한 액션/thunk를 정의하며, 해당 데이터 유형의 항목을 별도로 캐싱했습니다.
RTK Query를 사용하면 캐시 데이터 관리 로직이 애플리케이션당 단일 "API 슬라이스"로 중앙집중화됩니다. 앱당 단일 Redux 스토어를 가지는 것처럼, 이제는 모든 캐시 데이터를 위한 단일 슬라이스를 갖게 됩니다.
새로운 apiSlice.ts 파일 정의부터 시작하겠습니다. 이는 기존 "기능(features)"과 독립적이므로, 새로운 features/api/ 폴더를 생성하고 그 안에 apiSlice.ts를 배치하겠습니다. API 슬라이스 파일을 작성한 후 내부 코드를 분석해 보겠습니다:
// Import the RTK Query methods from the React-specific entry point
import { createApi, fetchBaseQuery } from '@reduxjs/toolkit/query/react'
// Use the `Post` type we've already defined in `postsSlice`,
// and then re-export it for ease of use
import type { Post } from '@/features/posts/postsSlice'
export type { Post }
// Define our single API slice object
export const apiSlice = createApi({
// The cache reducer expects to be added at `state.api` (already default - this is optional)
reducerPath: 'api',
// All of our requests will have URLs starting with '/fakeApi'
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
// The "endpoints" represent operations and requests for this server
endpoints: builder => ({
// The `getPosts` endpoint is a "query" operation that returns data.
// The return value is a `Post[]` array, and it takes no arguments.
getPosts: builder.query<Post[], void>({
// The URL for the request is '/fakeApi/posts'
query: () => '/posts'
})
})
})
// Export the auto-generated hook for the `getPosts` query endpoint
export const { useGetPostsQuery } = apiSlice
RTK Query의 기능은 createApi라는 단일 메서드를 기반으로 합니다. 지금까지 살펴본 Redux Toolkit API들은 모두 UI에 구애받지 않으며 어떤 UI 레이어와도 함께 사용할 수 있습니다. RTK Query 핵심 로직도 마찬가지입니다. 하지만 RTK Query는 React 전용 버전의 createApi도 포함하고 있으며, RTK와 React를 함께 사용하는 경우 RTK의 React 통합 기능을 활용하기 위해 이 버전을 사용해야 합니다. 따라서 특별히 '@reduxjs/toolkit/query/react'에서 임포트합니다.
애플리케이션에는 단 하나의 createApi 호출만 존재해야 합니다. 이 단일 API 슬라이스는 동일한 기본 URL과 통신하는 모든 엔드포인트 정의를 포함해야 합니다. 예를 들어 /api/posts와 /api/users 엔드포인트는 모두 동일한 서버에서 데이터를 가져오므로 동일한 API 슬라이스에 포함되어야 합니다. 애플리케이션이 여러 서버에서 데이터를 가져오는 경우 각 엔드포인트에 전체 URL을 명시하거나, 반드시 필요한 경우 서버별로 별도의 API 슬라이스를 생성할 수 있습니다.
엔드포인트는 일반적으로 createApi 호출 내부에 직접 정의됩니다. 엔드포인트를 여러 파일로 분할하려는 경우 문서의 8부 "엔드포인트 주입" 섹션을 참조하세요!
API 슬라이스 매개변수
createApi를 호출할 때 두 가지 필수가 필요합니다:
-
baseQuery: 서버에서 데이터를 가져오는 방법을 아는 함수입니다. RTK Query에는 표준fetch()함수를 감싸서 HTTP 요청 및 응답의 일반적인 처리를 담당하는fetchBaseQuery가 포함되어 있습니다.fetchBaseQuery인스턴스를 생성할 때 향후 모든 요청의 기본 URL을 전달할 수 있으며, 요청 헤더 수정과 같은 동작을 재정의할 수도 있습니다. 오류 처리 및 인증과 같은 동작을 사용자 정의하기 위해 사용자 정의 base 쿼리 생성이 가능합니다. -
endpoints: 이 서버와 상호작용하기 위해 정의한 작업 집합입니다. 엔드포인트는 데이터를 반환하여 캐싱하는 쿼리 또는 서버에 업데이트를 전송하는 뮤테이션이 될 수 있습니다. 엔드포인트는builder매개변수를 받는 콜백 함수로 정의되며,builder.query()및builder.mutation()으로 생성된 엔드포인트 정의를 포함하는 객체를 반환합니다.
createApi는 또한 생성된 리듀서의 최상위 상태 슬라이스 필드를 정의하는 reducerPath 필드를 받습니다. postsSlice와 같은 다른 슬라이스의 경우 state.posts를 업데이트하는 데 사용될 것이라는 보장이 없습니다. 루트 상태의 어디에든 리듀서를 연결할 수 있습니다(예: someOtherField: postsReducer). 여기서 createApi는 스토어에 캐시 리듀서를 추가할 때 캐시 상태가 존재할 위치를 알려주기를 기대합니다. reducerPath 옵션을 제공하지 않으면 기본값 'api'로 설정되므로 모든 RTKQ 캐시 데이터는 state.api 아래에 저장됩니다.
리듀서를 스토어에 추가하는 것을 잊었거나 reducerPath에 지정된 것과 다른 키에 연결하면 RTKQ가 오류를 기록하여 수정이 필요함을 알립니다.
엔드포인트 정의하기
모든 요청의 URL 첫 부분은 fetchBaseQuery 정의에서 '/fakeApi'로 정의됩니다.
첫 번째 단계로 가짜 API 서버에서 전체 게시글 목록을 반환하는 엔드포인트를 추가하려 합니다. getPosts라는 엔드포인트를 포함하고 builder.query()를 사용하여 쿼리 엔드포인트로 정의할 것입니다. 이 메서드는 요청 생성 및 응답 처리 방식을 구성하기 위한 많은 옵션을 받습니다. 지금은 URL 문자열을 반환하는 콜백인 () => '/posts'로 query 옵션을 제공하여 나머지 URL 경로 조각을 정의하기만 하면 됩니다.
기본적으로 쿼리 엔드포인트는 GET HTTP 요청을 사용하지만, URL 문자열 대신 {url: '/posts', method: 'POST', body: newPost} 같은 객체를 반환하여 이를 재정의할 수 있습니다. 이 방식으로 헤더 설정과 같은 여러 요청 옵션도 정의할 수 있습니다.
TypeScript 사용 시 builder.query()와 builder.mutation() 엔드포인트 정의 함수는 두 개의 제네릭 인수를 받습니다: <ReturnType, ArgumentType>. 예를 들어 이름으로 포켓몬을 조회하는 엔드포인트는 getPokemonByName: builder.query<Pokemon, string>()처럼 작성할 수 있습니다. 인수를 전혀 받지 않는 엔드포인트의 경우 getAllPokemon: builder.query<Pokemon[], void>()처럼 void 타입을 사용하세요.
API 슬라이스 및 훅 내보내기
이전 createSlice 함수에서는 다른 파일에서 필요한 부분이 액션 생성자와 슬라이스 리듀서뿐이었기 때문에 해당 부분만 내보내기만 하면 됐습니다. RTK Query에서는 여러 유용한 필드가 포함되어 있기 때문에 일반적으로 'API 슬라이스' 객체 전체를 내보냅니다.
마지막으로 이 파일의 끝 부분을 주목해 보세요. useGetPostsQuery 값은 어디서 온 걸까요?
RTK Query의 React 통합은 정의한 모든 엔드포인트에 대해 React 훅을 자동으로 생성합니다! 이 훅들은 컴포넌트 마운트 시 요청 트리거, 요청 처리 및 데이터 준비 과정에서의 컴포넌트 리렌더링을 캡슐화합니다. 이 훅들을 API 슬라이스 파일에서 내보내 React 컴포넌트에서 사용할 수 있습니다.
훅 이름은 표준 규칙에 따라 자동 생성됩니다:
-
모든 React 훅의 표준 접두사인
use -
첫 글자를 대문자로 표기한 엔드포인트 이름
-
엔드포인트 유형(
Query또는Mutation)
이 경우 엔드포인트는 getPosts이고 쿼리 유형이므로 생성된 훅은 useGetPostsQuery입니다.
스토어 구성하기
이제 API 슬라이스를 Redux 스토어에 연결해야 합니다. 기존 store.ts 파일을 수정하여 API 슬라이스의 캐시 리듀서를 상태에 추가할 수 있습니다. 또한 API 슬라이스가 생성한 커스텀 미들웨어를 스토어에 반드시 추가해야 합니다. 이 미들웨어는 캐시 수명과 만료를 관리합니다.
import { configureStore } from '@reduxjs/toolkit'
import { apiSlice } from '@/features/api/apiSlice'
import authReducer from '@/features/auth/authSlice'
import postsReducer from '@/features/posts/postsSlice'
import usersReducer from '@/features/users/usersSlice'
import notificationsReducer from '@/features/notifications/notificationsSlice'
import { listenerMiddleware } from './listenerMiddleware'
export const store = configureStore({
// Pass in the root reducer setup as the `reducer` argument
reducer: {
auth: authReducer,
posts: postsReducer,
users: usersReducer,
notifications: notificationsReducer,
[apiSlice.reducerPath]: apiSlice.reducer
},
middleware: getDefaultMiddleware =>
getDefaultMiddleware()
.prepend(listenerMiddleware.middleware)
.concat(apiSlice.middleware)
})
캐싱 리듀서가 올바른 위치에 추가되도록 reducer 매개변수에서 계산된 키로 apiSlice.reducerPath 필드를 재사용할 수 있습니다.
리스너 미들웨어 추가하기에서 확인했듯이, 스토어 설정 시 redux-thunk 같은 기존 표준 미들웨어를 모두 유지해야 하며, API 슬라이스 미들웨어는 일반적으로 이들 뒤에 위치합니다. 이미 getDefaultMiddleware()를 호출하고 리스너 미들웨어를 앞쪽에 배치했으므로, 끝에 추가하려면 .concat(apiSlice.middleware)를 호출하면 됩니다.
쿼리로 게시물 표시하기
컴포넌트에서 쿼리 훅 사용하기
API 슬라이스를 정의하고 스토어에 추가했으니, 생성된 useGetPostsQuery 훅을 <PostsList> 컴포넌트로 가져와 사용할 수 있습니다.
현재 <PostsList>는 useSelector, useDispatch, useEffect를 명시적으로 가져오고, 스토어에서 게시물 데이터와 로딩 상태를 읽으며, 마운트 시 fetchPosts() 썽크를 디스패치하여 데이터 가져오기를 트리거합니다. useGetPostsQueryHook이 이 모든 것을 대체합니다!
이 훅을 사용할 때 <PostsList>가 어떻게 변하는지 살펴보겠습니다:
import React from 'react'
import { Link } from 'react-router-dom'
import { Spinner } from '@/components/Spinner'
import { TimeAgo } from '@/components/TimeAgo'
import { useGetPostsQuery, Post } from '@/features/api/apiSlice'
import { PostAuthor } from './PostAuthor'
import { ReactionButtons } from './ReactionButtons'
// Go back to passing a `post` object as a prop
interface PostExcerptProps {
post: Post
}
function PostExcerpt({ post }: PostExcerptProps) {
return (
<article className="post-excerpt" key={post.id}>
<h3>
<Link to={`/posts/${post.id}`}>{post.title}</Link>
</h3>
<div>
<PostAuthor userId={post.user} />
<TimeAgo timestamp={post.date} />
</div>
<p className="post-content">{post.content.substring(0, 100)}</p>
<ReactionButtons post={post} />
</article>
)
}
export const PostsList = () => {
// Calling the `useGetPostsQuery()` hook automatically fetches data!
const {
data: posts = [],
isLoading,
isSuccess,
isError,
error
} = useGetPostsQuery()
let content: React.ReactNode
// Show loading states based on the hook status flags
if (isLoading) {
content = <Spinner text="Loading..." />
} else if (isSuccess) {
content = posts.map(post => <PostExcerpt key={post.id} post={post} />)
} else if (isError) {
content = <div>{error.toString()}</div>
}
return (
<section className="posts-list">
<h2>Posts</h2>
{content}
</section>
)
}
개념적으로 <PostsList>는 여전히 동일한 작업을 수행하지만, 여러 useSelector 호출과 useEffect 디스패치를 useGetPostsQuery() 단일 호출로 대체할 수 있었습니다.
(참고: 현재 시점에서는 아직 기존 state.posts 슬라이스의 데이터를 참조하는 코드와 RTK Query에서 데이터를 읽는 새로운 코드 사이에 불일치가 있을 수 있습니다. 이는 예상된 현상이며, 앞으로 하나씩 해결해 나갈 것입니다.)
이전에는 스토어에서 게시물 ID 목록을 선택하고, 각 <PostExcerpt> 컴포넌트에 게시물 ID를 전달한 다음, 스토어에서 개별 Post 객체를 별도로 선택했습니다. 이제 posts 배열에 모든 게시물 객체가 포함되어 있으므로, 게시물 객체 자체를 props로 직접 전달하는 방식으로 변경했습니다.
캐시된 데이터에 접근할 때는 일반적으로 쿼리 훅을 사용해야 합니다. 가져온 데이터에 접근하기 위해 직접 useSelector를 작성하거나 데이터 가져오기를 트리거하기 위해 useEffect를 사용해서는 안 됩니다!
쿼리 훅 결과 객체
생성된 각 쿼리 훅은 다음과 같은 필드를 포함하는 "결과" 객체를 반환합니다:
-
data: 서버로부터 받은 가장 최근의 성공적인 캐시 항목 데이터의 실제 응답 내용입니다. 응답을 받기 전까지 이 필드는undefined상태입니다. -
currentData: 현재 쿼리 인수에 대한 응답 내용입니다. 쿼리 인수가 변경되고 기존 캐시 항목이 없어 요청이 시작되면undefined로 전환될 수 있습니다. -
isLoading: 아직 데이터가 없어 서버에 첫 요청을 보내고 있는지 여부를 나타내는 불리언 값입니다(다른 데이터를 요청하기 위해 인수가 변경되더라도isLoading은 false로 유지됨). -
isFetching: 현재 서버에 요청을 보내고 있는지 여부를 나타내는 불리언 값입니다 -
isSuccess: 성공적인 요청을 완료하고 캐시된 데이터를 사용할 수 있는지 여부를 나타내는 불리언 값입니다(즉, 이제data가 정의되어 있어야 함) -
isError: 마지막 요청에 오류가 발생했는지 여부를 나타내는 불리언 값입니다 -
error: 직렬화된 오류 객체입니다
일반적으로 결과 객체에서 필드를 구조 분해하고, data를 posts처럼 더 구체적인 변수명으로 바꿔 내용을 설명합니다. 그런 다음 상태 불리언 값과 data/error 필드를 사용하여 원하는 UI를 렌더링할 수 있습니다. 단, 구버전 TypeScript를 사용하는 경우 TS가 data의 유효성을 올바르게 추론할 수 있도록 원본 객체를 그대로 유지하고 조건문에서 result.isSuccess와 같이 플래그를 참조해야 할 수 있습니다.
로딩 상태 필드
isLoading과 isFetching은 서로 다른 동작을 하는 별개의 플래그입니다. UI에서 로딩 상태를 표시해야 하는 시점과 방식에 따라 사용할 플래그를 결정할 수 있습니다. 예를 들어, 페이지를 처음 로드할 때 스켈레톤을 표시하려면 isLoading을 확인할 수 있습니다. 또는 사용자가 다른 항목을 선택할 때마다 발생하는 요청에 대해 스피너를 표시하거나 기존 결과를 회색 처리하려면 isFetching을 확인할 수 있습니다.
마찬가지로 data와 currentData는 서로 다른 시점에 변경됩니다. 대부분의 경우 data의 값을 사용해야 하지만, 로딩 동작을 더 세밀하게 제어하려면 currentData를 사용할 수 있습니다. 예를 들어 재가져오기 상태를 나타내기 위해 UI에서 데이터를 반투명하게 표시하려면 isFetching과 함께 data를 사용하면 됩니다. 새 요청이 완료될 때까지 data가 동일하게 유지되기 때문입니다. 그러나 새 요청이 완료될 때까지 UI를 비우는 것처럼 현재 인수에 해당하는 값만 표시하려면 currentData를 사용할 수 있습니다.
게시물 정렬
현재 게시물이 순서 없이 표시되고 있습니다. 이전에는 createEntityAdapter의 정렬 옵션을 사용해 리듀서 수준에서 날짜별로 정렬했습니다. API 슬라이스는 서버에서 반환된 배열을 그대로 캐싱하기 때문에 특정 정렬이 발생하지 않습니다. 서버가 반환한 순서 그대로 표시되는 것입니다.
이 문제를 처리하는 방법에는 몇 가지 옵션이 있습니다. 지금은 정렬을 <PostsList> 내부에서 수행하고, 다른 옵션과 그 장단점에 대해서는 나중에 논의하겠습니다.
Array.sort()는 기존 배열을 변형(mutate)하기 때문에 posts.sort()를 직접 호출할 수 없습니다. 따라서 먼저 배열 복사본을 만들어야 합니다. 리렌더링 시마다 재정렬을 방지하기 위해 useMemo() 훅 내에서 정렬을 수행할 수 있습니다. 또한 posts가 undefined일 경우를 대비해 기본값으로 빈 배열을 설정하여 항상 정렬 가능한 배열을 확보합니다.
// omit setup
export const PostsList = () => {
const {
data: posts = [],
isLoading,
isSuccess,
isError,
error
} = useGetPostsQuery()
const sortedPosts = useMemo(() => {
const sortedPosts = posts.slice()
// Sort posts in descending chronological order
sortedPosts.sort((a, b) => b.date.localeCompare(a.date))
return sortedPosts
}, [posts])
let content
if (isLoading) {
content = <Spinner text="Loading..." />
} else if (isSuccess) {
content = sortedPosts.map(post => <PostExcerpt key={post.id} post={post} />)
} else if (isError) {
content = <div>{error.toString()}</div>
}
// omit rendering
}
개별 게시물 표시하기
<PostsList>를 업데이트하여 모든 게시물 목록을 가져오고 목록 내에 각 Post의 일부를 표시하도록 했습니다. 하지만 그 중 하나의 "게시물 보기"를 클릭하면, <SinglePostPage> 컴포넌트가 기존 state.posts 슬라이스에서 게시물을 찾지 못하고 "게시물을 찾을 수 없습니다!" 오류가 발생합니다. <SinglePostPage>도 RTK Query를 사용하도록 업데이트해야 합니다.
이를 구현하는 방법에는 여러 가지가 있습니다. 한 가지 방법은 <SinglePostPage>가 동일한 useGetPostsQuery() 훅을 호출하여 게시물 전체 배열을 가져온 다음 표시할 특정 Post 객체만 찾는 것입니다. 쿼리 훅에는 selectFromResult 옵션도 있어서 훅 자체 내에서 이 조회를 더 일찍 수행할 수 있습니다. 이는 나중에 실제 사례에서 확인하겠습니다.
대신 서버에서 ID 기반으로 단일 게시물을 요청할 수 있도록 새 엔드포인트 정의를 추가해 보겠습니다. 다소 중복되지만, 인수 기반으로 쿼리 요청을 커스터마이징하는 RTK Query의 활용 방식을 확인할 수 있습니다.
단일 게시물 쿼리 엔드포인트 추가하기
apiSlice.ts에 getPost('s' 없음)라는 새 쿼리 엔드포인트 정의를 추가합니다:
export const apiSlice = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
endpoints: builder => ({
getPosts: builder.query<Post[], void>({
query: () => '/posts'
}),
getPost: builder.query<Post, string>({
query: postId => `/posts/${postId}`
})
})
})
export const { useGetPostsQuery, useGetPostQuery } = apiSlice
getPost 엔드포인트는 기존 getPosts와 유사하지만 query 매개변수가 다릅니다. 여기서 query는 postId 인수를 받아 해당 postId를 사용해 서버 URL을 구성합니다. 이렇게 하면 특정 Post 객체 하나만 서버에 요청할 수 있습니다.
이를 통해 새로운 useGetPostQuery 훅이 생성되므로 함께 내보냅니다.
쿼리 인수와 캐시 키
현재 <SinglePostPage>는 ID 기반으로 state.posts에서 Post 항목 하나를 읽습니다. 이를 새로운 useGetPostQuery 훅을 호출하고 메인 목록과 유사한 로딩 상태를 사용하도록 업데이트해야 합니다.
// omit some imports
import { useGetPostQuery } from '@/features/api/apiSlice'
import { selectCurrentUsername } from '@/features/auth/authSlice'
export const SinglePostPage = () => {
const { postId } = useParams()
const currentUsername = useAppSelector(selectCurrentUsername)
const { data: post, isFetching, isSuccess } = useGetPostQuery(postId!)
let content: React.ReactNode
const canEdit = currentUsername === post?.user
if (isFetching) {
content = <Spinner text="Loading..." />
} else if (isSuccess) {
content = (
<article className="post">
<h2>{post.title}</h2>
<div>
<PostAuthor userId={post.user} />
<TimeAgo timestamp={post.date} />
</div>
<p className="post-content">{post.content}</p>
<ReactionButtons post={post} />
{canEdit && (
<Link to={`/editPost/${post.id}`} className="button">
Edit Post
</Link>
)}
</article>
)
}
return <section>{content}</section>
}
라우터 매치에서 읽어온 postId를 가져와 useGetPostQuery의 인수로 전달합니다. 쿼리 훅은 이를 사용해 요청 URL을 구성하고 특정 Post 객체를 가져옵니다.
그렇다면 이 모든 데이터는 어떻게 캐시될까요? 게시물 항목 하나에 "게시물 보기"를 클릭한 후 이 시점의 Redux 스토어 내부를 살펴보겠습니다.
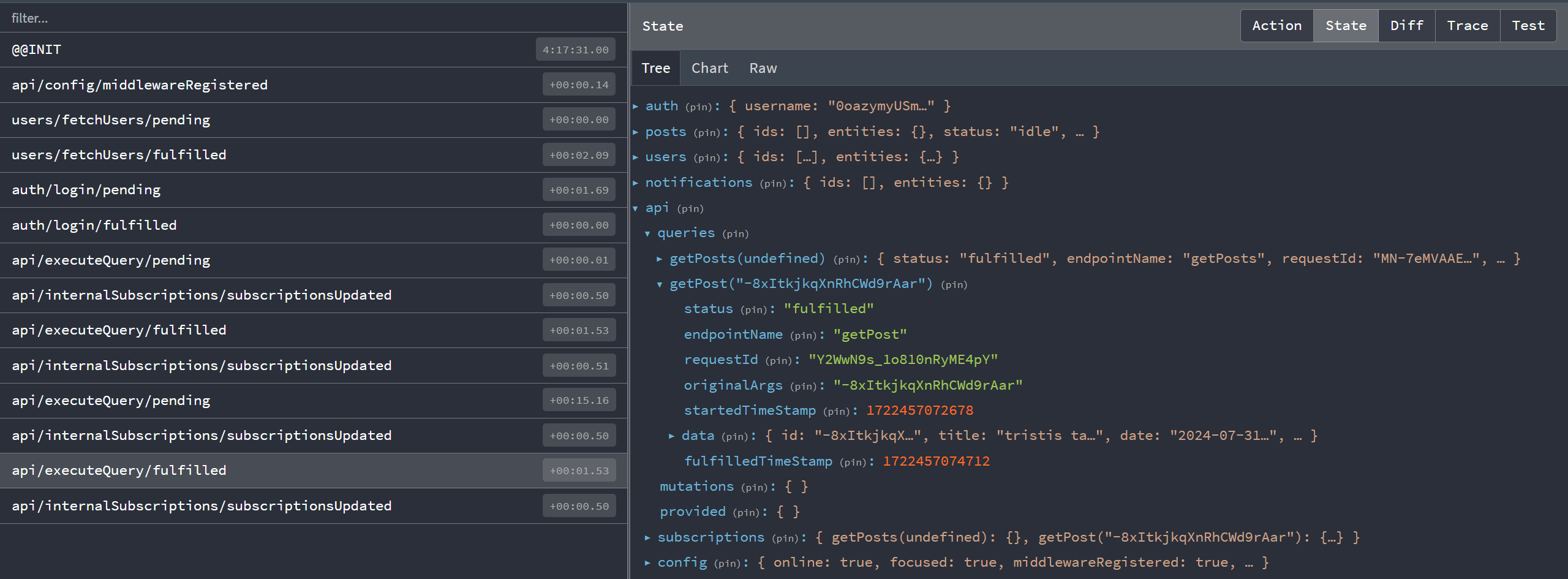
스토어 설정에서 예상한 대로 최상위 state.api 슬라이스가 있음을 볼 수 있습니다. 그 안에는 queries 섹션이 있으며 현재 두 항목이 있습니다. getPosts(undefined) 키는 getPosts 엔드포인트로 수행한 요청의 메타데이터와 응답 내용을 나타냅니다. 마찬가지로 getPost('abcd1234') 키는 방금 이 게시물에 대해 수행한 특정 요청을 의미합니다.
RTK Query는 각 고유한 엔드포인트 + 인수 조합에 대해 "캐시 키"를 생성하고, 각 캐시 키의 결과를 별도로 저장합니다. 이는 동일한 쿼리 훅을 여러 번 사용하면서 서로 다른 쿼리 매개변수를 전달할 수 있으며, 각 결과가 Redux 스토어에 별도로 캐시된다는 것을 의미합니다.
동일한 데이터를 여러 컴포넌트에서 사용해야 하는 경우, 각 컴포넌트에서 동일한 인자로 동일한 쿼리 훅을 호출하기만 하면 됩니다! 예를 들어 세 개의 다른 컴포넌트에서 useGetPostQuery('123')을 호출하면 RTK Query가 데이터를 단 한 번만 가져오도록 보장하며, 필요 시 각 컴포넌트가 리렌더링됩니다.
쿼리 매개변수는 반드시 단일 값이어야 한다는 점 또한 중요합니다! 여러 매개변수를 전달해야 하는 경우 객체를 전달해야 하며(createAsyncThunk와 정확히 동일함), 이때 RTK Query는 필드에 대해 "얕은 안정성(shallow stable)" 비교를 수행하여 변경된 값이 있을 경우 데이터를 재요청합니다.
왼쪽 목록의 액션 이름(posts/fetchPosts/fulfilled 대신 api/executeQuery/fulfilled)이 더 일반적이고 덜 구체적인 것을 알 수 있습니다. 이는 추가적인 추상화 계층을 사용할 때의 절충점입니다. 개별 액션은 action.meta.arg.endpointName 아래에 특정 엔드포인트 이름을 포함하지만, 액션 기록 목록에서는 쉽게 확인하기 어렵습니다.
Redux DevTools에는 "RTK Query" 탭이 포함되어 있어, 원시 Redux 상태 구조보다는 캐시 항목에 초점을 맞춘 더 유용한 형식으로 RTK Query 데이터를 표시합니다. 여기에는 각 엔드포인트 및 캐시 결과 정보, 쿼리 시간 통계 등이 포함됩니다:
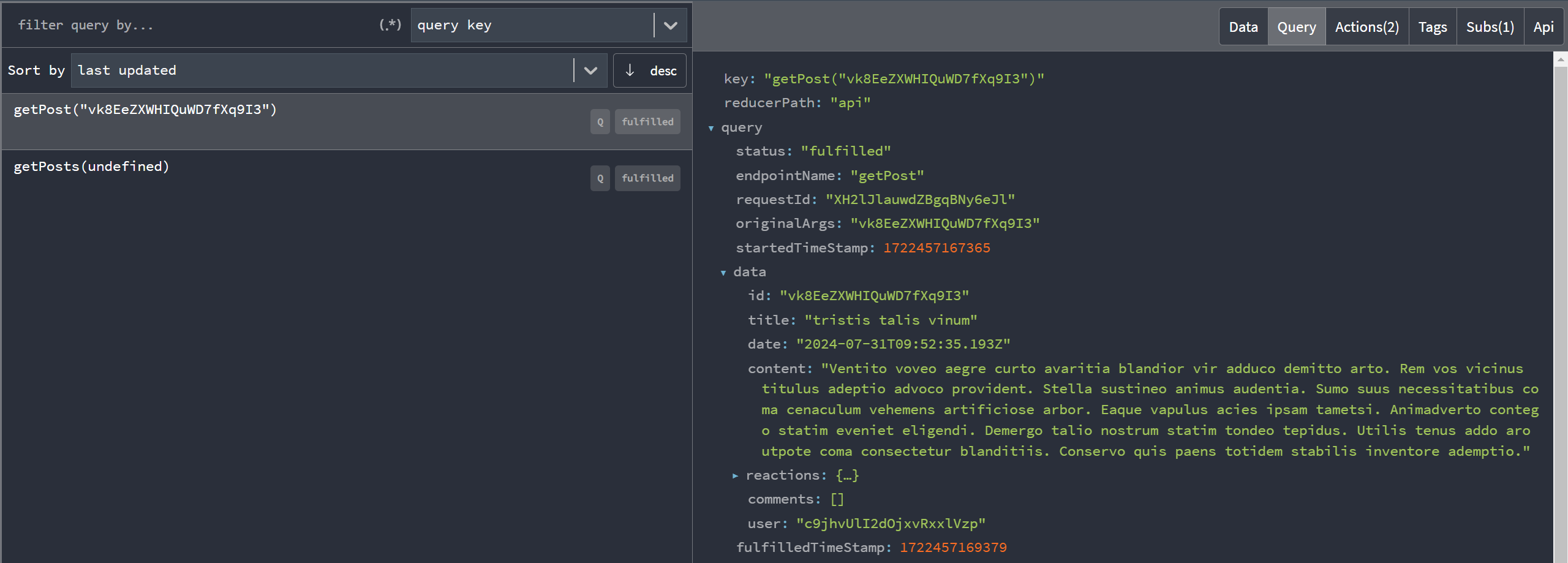
다음에서 RTK Query 개발 도구의 라이브 데모도 확인할 수 있습니다:
뮤테이션으로 게시물 생성하기
서버에서 데이터를 가져오기 위해 "쿼리" 엔드포인트를 정의하는 방법을 살펴보았습니다. 그렇다면 서버에 업데이트를 전송하는 것은 어떻게 할까요?
RTK Query를 사용하면 서버의 데이터를 업데이트하는 뮤테이션 엔드포인트를 정의할 수 있습니다. 새 게시물을 추가할 수 있는 뮤테이션을 추가해 보겠습니다.
새 게시물 뮤테이션 엔드포인트 추가
뮤테이션 엔드포인트 추가는 쿼리 엔드포인트 추가와 매우 유사합니다. 가장 큰 차이점은 builder.query() 대신 builder.mutation()을 사용해 엔드포인트를 정의한다는 점입니다. 또한 이제 HTTP 메서드를 'POST' 요청으로 변경해야 하며 요청 본문도 함께 제공해야 합니다.
컴포넌트에서 전달해야 하는 값이므로 postsSlice.ts에서 기존 NewPost TS 타입을 내보낸 후, 이 뮤테이션의 인자 타입으로 사용합니다.
import { createApi, fetchBaseQuery } from '@reduxjs/toolkit/query/react'
import type { Post, NewPost } from '@/features/posts/postsSlice'
export type { Post }
export const apiSlice = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
endpoints: builder => ({
getPosts: builder.query<Post[], void>({
query: () => '/posts'
}),
getPost: builder.query<Post, string>({
query: postId => `/posts/${postId}`
}),
addNewPost: builder.mutation<Post, NewPost>({
query: initialPost => ({
// The HTTP URL will be '/fakeApi/posts'
url: '/posts',
// This is an HTTP POST request, sending an update
method: 'POST',
// Include the entire post object as the body of the request
body: initialPost
})
})
})
})
export const {
useGetPostsQuery,
useGetPostQuery,
useAddNewPostMutation
} = apiSlice
쿼리 엔드포인트와 마찬가지로 TS 타입을 지정합니다: 뮤테이션은 전체 Post를 반환하며, 인자로 부분적 NewPost 값을 받습니다.
여기서 query 옵션은 {url, method, body}를 포함하는 객체를 반환하며, 이를 통해 HTTP POST 메서드 요청임을 지정하고 body 내용이 무엇인지 정의할 수 있습니다. 요청 생성에 fetchBaseQuery를 사용하므로 body 필드는 자동으로 JSON 직렬화됩니다. (예, 이 예제에서 "post"라는 단어가 지나치게 많이 등장합니다 :) )
쿼리 엔드포인트와 마찬가지로 API 슬라이스는 뮤테이션 엔드포인트에 대한 React 훅(이 경우 useAddNewPostMutation)을 자동으로 생성합니다.
컴포넌트에서 뮤테이션 훅 사용하기
현재 <AddPostForm>은 "게시물 저장" 버튼을 클릭할 때마다 게시물을 추가하기 위해 비동기 Thunk를 디스패치하고 있습니다. 이를 위해 useDispatch와 addNewPost Thunk를 가져와야 합니다. 뮤테이션 훅은 이 두 가지를 모두 대체하며, 사용 패턴은 기본적으로 동일합니다:
import React from 'react'
import { useAppSelector } from '@/app/hooks'
import { useAddNewPostMutation } from '@/features/api/apiSlice'
import { selectCurrentUsername } from '@/features/auth/authSlice'
// omit field types
export const AddPostForm = () => {
const userId = useAppSelector(selectCurrentUsername)!
const [addNewPost, { isLoading }] = useAddNewPostMutation()
const handleSubmit = async (e: React.FormEvent<AddPostFormElements>) => {
// Prevent server submission
e.preventDefault()
const { elements } = e.currentTarget
const title = elements.postTitle.value
const content = elements.postContent.value
const form = e.currentTarget
try {
await addNewPost({ title, content, user: userId }).unwrap()
form.reset()
} catch (err) {
console.error('Failed to save the post: ', err)
}
}
return (
<section>
<h2>Add a New Post</h2>
<form onSubmit={handleSubmit}>
<label htmlFor="postTitle">Post Title:</label>
<input
type="text"
id="postTitle"
name="postTitle"
defaultValue=""
required
/>
<label htmlFor="postContent">Content:</label>
<textarea
id="postContent"
name="postContent"
defaultValue=""
required
/>
<button disabled={isLoading}>Save Post</button>
</form>
</section>
)
}
뮤테이션 훅은 두 개의 값을 가진 배열을 반환합니다:
-
첫 번째 값은 "트리거 함수"입니다. 호출 시 제공한 인자와 함께 서버에 요청을 보냅니다. 이는 실제로 즉시 디스패치되도록 래핑된 Thunk입니다.
-
두 번째 값은 진행 중인 요청에 대한 메타데이터를 포함하는 객체입니다(요청이 있는 경우). 여기에는 요청 진행 여부를 나타내는
isLoading플래그가 포함됩니다.
기존의 thunk dispatch와 컴포넌트 로딩 상태를 useAddNewPostMutation 훅의 트리거 함수와 isLoading 플래그로 대체할 수 있으며, 컴포넌트의 나머지 부분은 동일하게 유지됩니다.
이전 thunk dispatch와 마찬가지로 초기 게시물 객체와 함께 addNewPost을 호출합니다. 이는 .unwrap() 메서드가 포함된 특별한 Promise를 반환하며, await addNewPost().unwrap()을 사용해 표준 try/catch 블록으로 잠재적 오류를 처리할 수 있습니다. (이는 createAsyncThunk 사용 시와 동일하게 보이는데, 실제로도 동일하기 때문입니다—RTK Query는 내부적으로 createAsyncThunk를 사용합니다)
캐시 데이터 갱신
"Save Post"를 클릭하면 브라우저 DevTools의 Network 탭에서 HTTP POST 요청이 성공했음을 확인할 수 있습니다. 하지만 <PostsList>로 돌아가면 새 게시물이 표시되지 않습니다. Redux 스토어 상태는 변경되지 않았으며 메모리에 동일한 캐시 데이터가 남아 있습니다.
방금 추가한 새 게시물을 보려면 RTK Query에 게시물 캐시 목록을 갱신하도록 지시해야 합니다.
게시물 수동 재요청
첫 번째 옵션은 특정 엔드포인트에 대해 RTK Query가 데이터를 재요청하도록 수동으로 강제하는 것입니다. 실제 앱에서 사용할 방법은 아니지만, 중간 단계로 지금 시도해 보겠습니다.
쿼리 훅 결과 객체에는 재요청을 강제로 트리거할 수 있는 refetch 함수가 포함됩니다. <PostsList>에 "게시물 재요청" 버튼을 임시로 추가하고 새 게시물 추가 후 클릭할 수 있습니다:
export const PostsList = () => {
const {
data: posts = [],
isLoading,
isSuccess,
isError,
error,
refetch
} = useGetPostsQuery()
// omit content
return (
<section className="posts-list">
<h2>Posts</h2>
<button onClick={refetch}>Refetch Posts</button>
{content}
</section>
)
}
이제 새 게시물을 추가하고 완료될 때까지 기다린 후 "게시물 재요청"을 클릭하면 새 게시물이 표시되어야 합니다.
불행히도 재요청 발생을 알리는 실제 표시기가 없습니다. 재요청이 진행 중임을 나타내는 _무언가_를 표시하는 것이 도움이 될 것입니다.
앞서 쿼리 훅에는 데이터에 대한 첫 번째 요청 시 true가 되는 isLoading 플래그와, 데이터 요청이 진행 중일 때 항상 true가 되는 isFetching 플래그가 모두 있음을 확인했습니다. isFetching 플래그를 확인하고 재요청 진행 중 로딩 스피너로 전체 게시물 목록을 다시 교체할 수 있습니다. 하지만 이는 다소 성가실 수 있으며, 무엇보다도 이미 모든 게시물을 가지고 있는데 왜 완전히 숨겨야 할까요?
대신 기존 게시물 목록을 부분적으로 투명하게 만들어 데이터가 최신이 아님을 표시하되, 재요청 중에는 계속 표시되도록 할 수 있습니다. 요청이 완료되는 즉시 게시물 목록을 정상적으로 표시할 수 있습니다.
import classnames from 'classnames'
import { useGetPostsQuery, Post } from '@/features/api/apiSlice'
// omit other imports and PostExcerpt
export const PostsList = () => {
const {
data: posts = [],
isLoading,
isFetching,
isSuccess,
isError,
error,
refetch
} = useGetPostsQuery()
const sortedPosts = useMemo(() => {
const sortedPosts = posts.slice()
sortedPosts.sort((a, b) => b.date.localeCompare(a.date))
return sortedPosts
}, [posts])
let content: React.ReactNode
if (isLoading) {
content = <Spinner text="Loading..." />
} else if (isSuccess) {
const renderedPosts = sortedPosts.map(post => (
<PostExcerpt key={post.id} post={post} />
))
const containerClassname = classnames('posts-container', {
disabled: isFetching
})
content = <div className={containerClassname}>{renderedPosts}</div>
} else if (isError) {
content = <div>{error.toString()}</div>
}
// omit return
}
새 게시물을 추가한 후 "게시물 재요청"을 클릭하면 이제 게시물 목록이 몇 초간 반투명 상태가 된 후 상단에 새 게시물이 추가되어 다시 렌더링되는 것을 볼 수 있습니다.
캐시 무효화를 통한 자동 갱신
사용자 동작에 따라 수동으로 데이터 재요청을 강제하는 것은 때때로 필요하지만, 일반적인 사용에는 확실히 좋은 해결책이 아닙니다.
우리의 "서버"에는 방금 추가한 게시물을 포함한 모든 게시물의 전체 목록이 있습니다. 이상적으로는 변이(mutation) 요청이 완료되는 즉시 앱이 업데이트된 게시물 목록을 자동으로 재요청하도록 하는 것입니다. 이렇게 하면 클라이언트 측 캐시 데이터가 서버와 동기화되었음을 알 수 있습니다.
RTK Query는 "태그(tags)"를 사용해 쿼리와 변이 간의 관계를 정의하여 자동 데이터 재요청을 가능하게 합니다. "태그"는 특정 유형의 데이터에 식별자를 부여하고 캐시 일부를 "무효화(invalidate)"할 수 있게 해주는 문자열 또는 작은 객체입니다. 캐시 태그가 무효화되면 RTK Query는 해당 태그로 표시된 엔드포인트를 자동으로 재요청합니다.
기본 태그 사용에는 API 슬라이스에 세 가지 정보를 추가해야 합니다:
-
API 슬라이스 객체의 루트
tagTypes필드:'Post'와 같은 데이터 유형에 대한 문자열 태그 이름 배열 선언 -
쿼리 엔드포인트의
providesTags배열: 해당 쿼리의 데이터를 설명하는 태그 세트 목록 -
뮤테이션 엔드포인트의
invalidatesTags배열: 해당 뮤테이션이 실행될 때마다 무효화되는 태그 세트 목록
API 슬라이스에 단일 태그 'Post'를 추가하면 새 게시물을 추가할 때마다 getPosts 엔드포인트가 자동으로 재요청됩니다:
export const apiSlice = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
tagTypes: ['Post'],
endpoints: builder => ({
getPosts: builder.query<Post[], void>({
query: () => '/posts',
providesTags: ['Post']
}),
getPost: builder.query<Post, string>({
query: postId => `/posts/${postId}`
}),
addNewPost: builder.mutation<Post, NewPost>({
query: initialPost => ({
url: '/posts',
method: 'POST',
body: initialPost
}),
invalidatesTags: ['Post']
})
})
})
이것만으로 충분합니다! 이제 "Save Post"를 클릭하면 몇 초 후 <PostsList> 컴포넌트가 자동으로 회색으로 변했다가 새로 추가된 게시물이 상단에 나타나는 걸 볼 수 있습니다.
여기서 'Post' 문자열 자체에는 특별한 의미가 없습니다. 'Fred', 'qwerty' 등 어떤 문자열이든 가능합니다. 중요한 것은 각 필드에서 동일한 문자열을 사용하여 RTK Query가 "이 뮤테이션이 발생하면 동일한 태그 문자열이 등록된 모든 엔드포인트를 무효화하라"고 인식할 수 있게 하는 것입니다.
학습 내용 요약
RTK Query를 사용하면 데이터 패칭, 캐싱, 로딩 상태 관리의 실제 세부 사항이 추상화됩니다. 이는 애플리케이션 코드를 상당히 간소화하며, 의도한 앱 동작에 대한 상위 수준의 고민에 집중할 수 있게 합니다. RTK Query는 우리가 이미 본 Redux Toolkit API를 사용해 구현되었으므로 Redux DevTools를 통해 시간에 따른 상태 변화를 계속 확인할 수 있습니다.
- RTK Query는 Redux Toolkit에 포함된 데이터 패칭 및 캐싱 솔루션입니다
- 서버 데이터 캐시 관리를 추상화하며 로딩 상태, 결과 저장, 요청 생성 로직 작성을 제거합니다
- 비동기 thunk와 같은 Redux 패턴 위에 구축됩니다
- RTK Query는 애플리케이션당 단일 "API 슬라이스"를 사용하며
createApi로 정의합니다- UI 독립형 및 React 전용 버전의
createApi를 제공합니다 - API 슬라이스는 다양한 서버 작업을 위한 "엔드포인트"를 정의합니다
- React 통합 사용 시 자동 생성된 React 훅을 포함합니다
- UI 독립형 및 React 전용 버전의
- 쿼리 엔드포인트는 서버에서 데이터를 가져와 캐싱합니다
- 쿼리 훅은
data값과 로딩 상태 플래그를 반환합니다 - 수동 재요청 또는 "태그" 기반 캐시 무효화로 자동 재요청이 가능합니다
- 쿼리 훅은
- 뮤테이션 엔드포인트는 서버 데이터를 업데이트합니다
- 뮤테이션 훅은 업데이트 요청을 전송하는 트리거 함수와 로딩 상태를 반환합니다
- 트리거 함수는 "언래핑"되어 기다릴 수 있는 Promise를 반환합니다
다음 단계
RTK Query는 견고한 기본 동작을 제공하지만 요청 관리 및 캐시 데이터 작업을 커스터마이징할 수 있는 다양한 옵션도 포함합니다. Part 8: RTK Query 고급 패턴에서는 낙관적 업데이트 같은 유용한 기능 구현 방법을 살펴보겠습니다.